彻底搞懂 Cache
彻底搞懂 Cache
第1章 局部性原理
存在两种局部性:
1.1 时间局部性
时间局部性指被访问的存储单元在一个较短时间间隔可能又被访问。
时间局部性实际上是指一个元素在时间尺度上是可能被高频次访问的。
1.2 空间局部性
空间局部性指被访问的存储单元,其临近单元在一个较短时间间隔可能又被访问。
空间局部性实际上是指一个元素的相邻元素在时间尺度上是可能被高频次访问的。
第2章 cache的工作原理
Cache是一种位于CPU和主存之间的小容量、高速度的存储器。 其主要作用是弥补CPU与主存之间的速度差异,从而提高系统整体性能。
图 2.1 给出了一个使用cache的设计框图。 在CPU和总线之间使用了一个cache缓存经常访问的数据,可以有效的提高数据存取的效率,减少bus的带宽消耗。
Note:本章节例子中数据发起者是CPU,终端是主存。
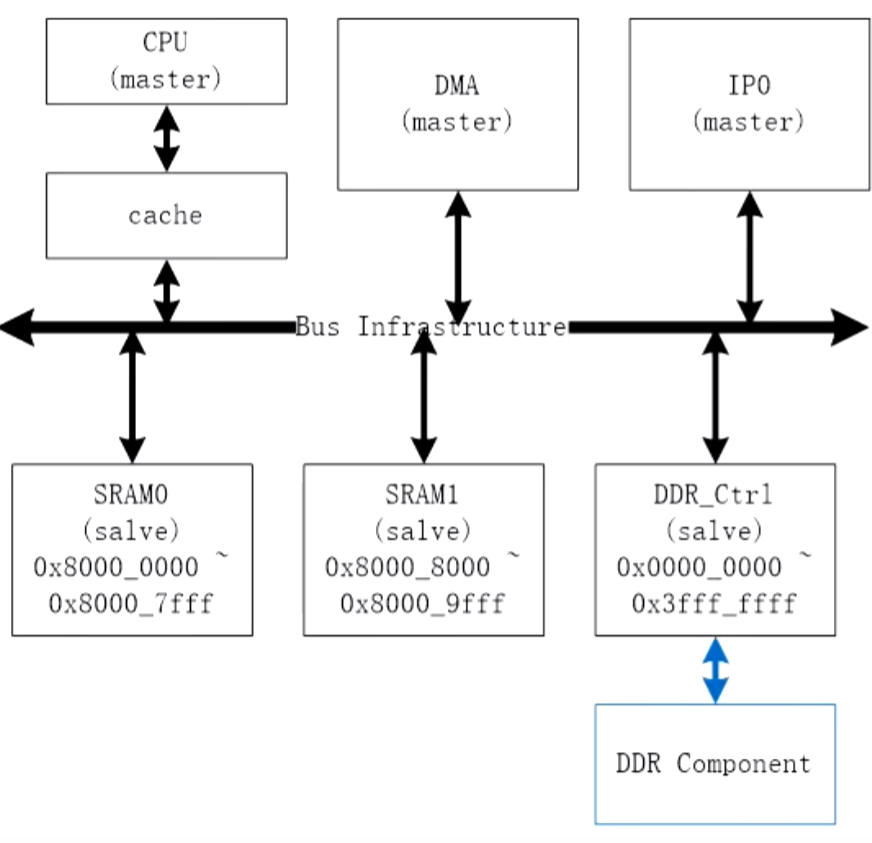
2.1 cache地址和主存地址
主存块:对主存地址以块进行划分。
缓存行:对缓存地址以行进行划分。
主存块和缓存行大小是完全相同的,且地址是一一映射的。
由于cache中只有主存中部分数据的副本,因此cache容量是远小于主存的。
为了兼顾cache的大小和速度,可以氛围三种cache: L1:速度最快,大小最小; L2:速度适中,大小适中; L3:速度最慢,大小最大。
2.2 缓存行和主存块
2.2.1 缓存地址
cache地址的结构中,高位存储cache的行号,低位存储cache的块内地址,如 表 2.1 所示。
表 2.1 缓存地址
| cache行号 | 块内地址 |
|---|
2.2.2 主存地址
主存地址的结构中,高位存储主存的块号,低位存储cache的块内地址,如 表 2.2 所示。
表 2.2 主存地址
| 主存块号 | 块内地址 |
|---|
2.2.3 缓存行的标志位与操作
缓存行存在两种标志位:
valid位:cache line 是否有有效数据。
dirty位:用来表示缓存行是否被修改过。
valid位
有效位存在于缓存行的高位,如 表 2.3 所示。
表 2.3 有效位
| 有效位 | 数据 |
|---|
- 如果缓存行的数据要被更新,先要调用
invalidate命令清除validflag。 cache line中的数据实际是存在的,只是被标记为无效。再进行覆盖写入。
dirty位
脏位存在于缓存行的高位,如 表 2.4 所示。
表 2.4 有效位
| 脏位 | 数据 |
|---|
- 如果缓存行被修改过,则该位被标记为
dirty的,此时数据需要flush到主存中,然后该位被标记为clean。
2.2.3 主存块直接映射到缓冲行
每个主存块映射到缓存的固定行主。
主存块和缓存行的快内地址是相同的,由于容量的差别,主存块号要比缓存行号大很多, 直接映射的方法将主存块号和缓存行号的差值作为缓存行的TAG位。如 图 2.2 所示。
Note:tag会出现在缓存行和主存地址中。tag属于标记位。缓存行号和快内地址不会出现在缓存行内。
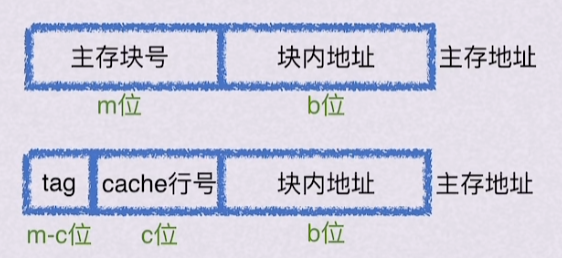
访存过程:
- CPU给出主存地址。
- 根据主存地址的缓存行位找到对应的缓存行。
- 对比缓存行和主存地址的tag位,并观察缓存行的有效位,
- 若tag相等,valid位为1,则缓存行hit。根据主存地址低位的块内地址在缓存行内锁定相应的存储单元并存取信息。
- 若tag不相等,或valid为0,则缓存行miss。cpu从主存读出主存地址的信息,送到缓存行,并设置tag位,将有效位置为1。同时将数据送到zpu。
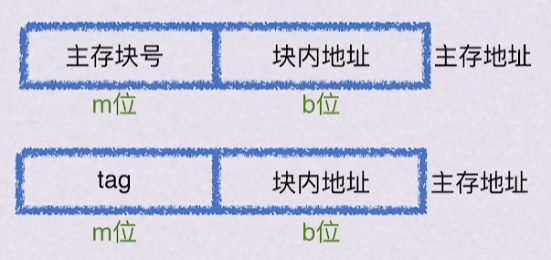
2.2.4 主存块全相联映射到缓存行
每个主存块映射到缓存的任意行。
主存块号全部作为tag位映射,如 图 2.3 所示。
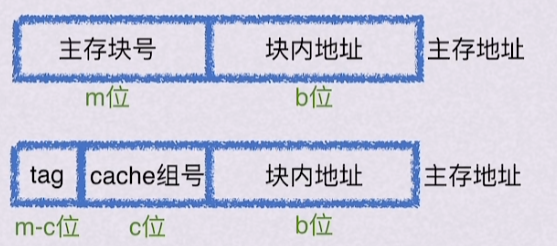
2.2.5 主存块组相联映射到缓存行
每个主存块映射到缓存固定组的任意行中。
全相联映射是将主存地址映射到缓存某个固定组内。如图 图 2.4 所示。
2.2.6 cache line
图 2.5 展示了一条bank的cache line位置示意图。
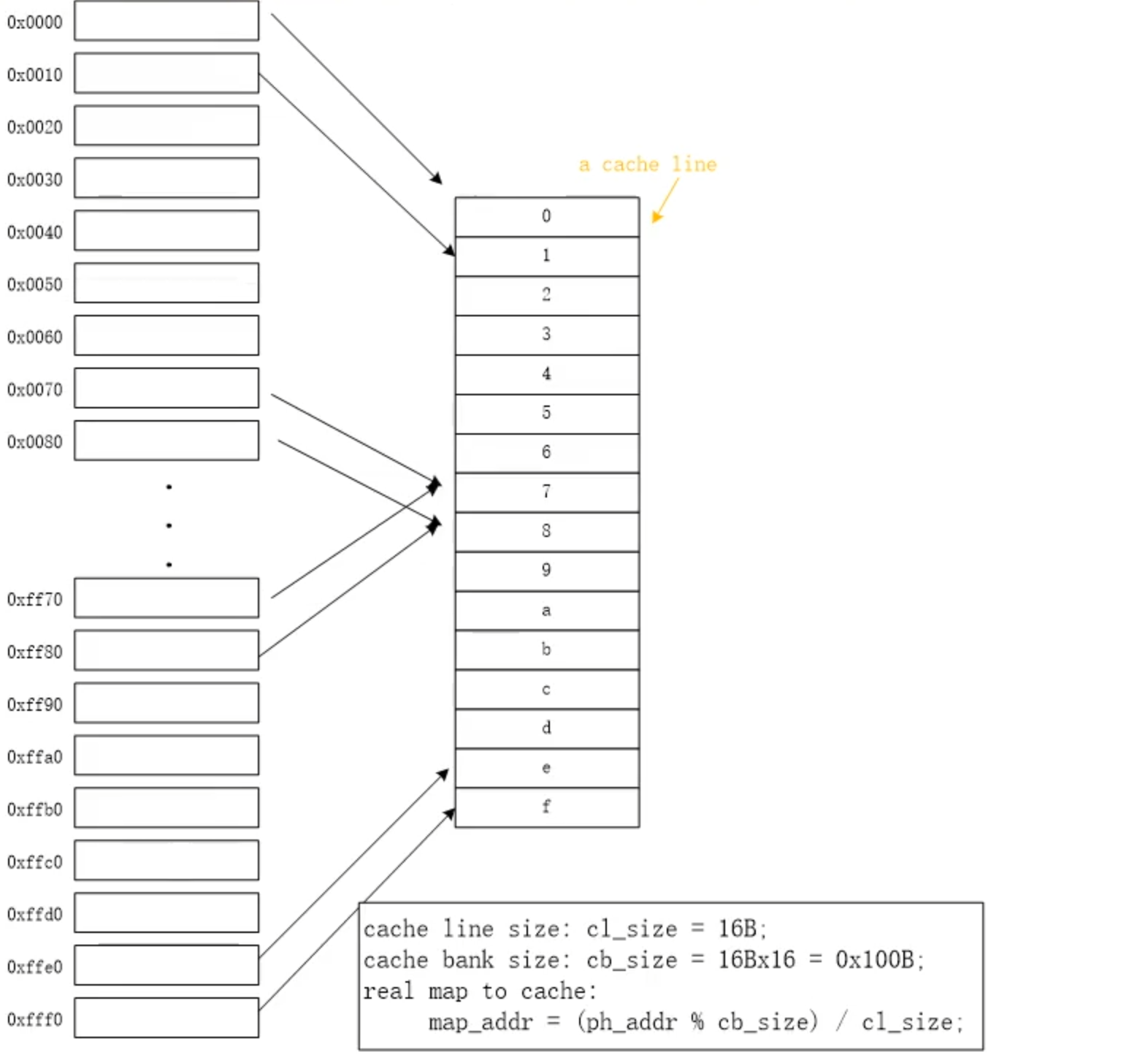
在 图 2.5 中: cache line的大小是0x10cache bank的大小是0x100
对于地址0x000的cache line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0x000 % 0x100) / 0x10
= 0
对于地址0x010的cache line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0x10 % 0x100) * 0x10
= 1
对于地址0xn0的cache_line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0xn0 % 0x100) / 0x10
= n
对于物理地址超出一个bank大小的cache,使用两个bank。图 2.6 给出了两个bank的例子。
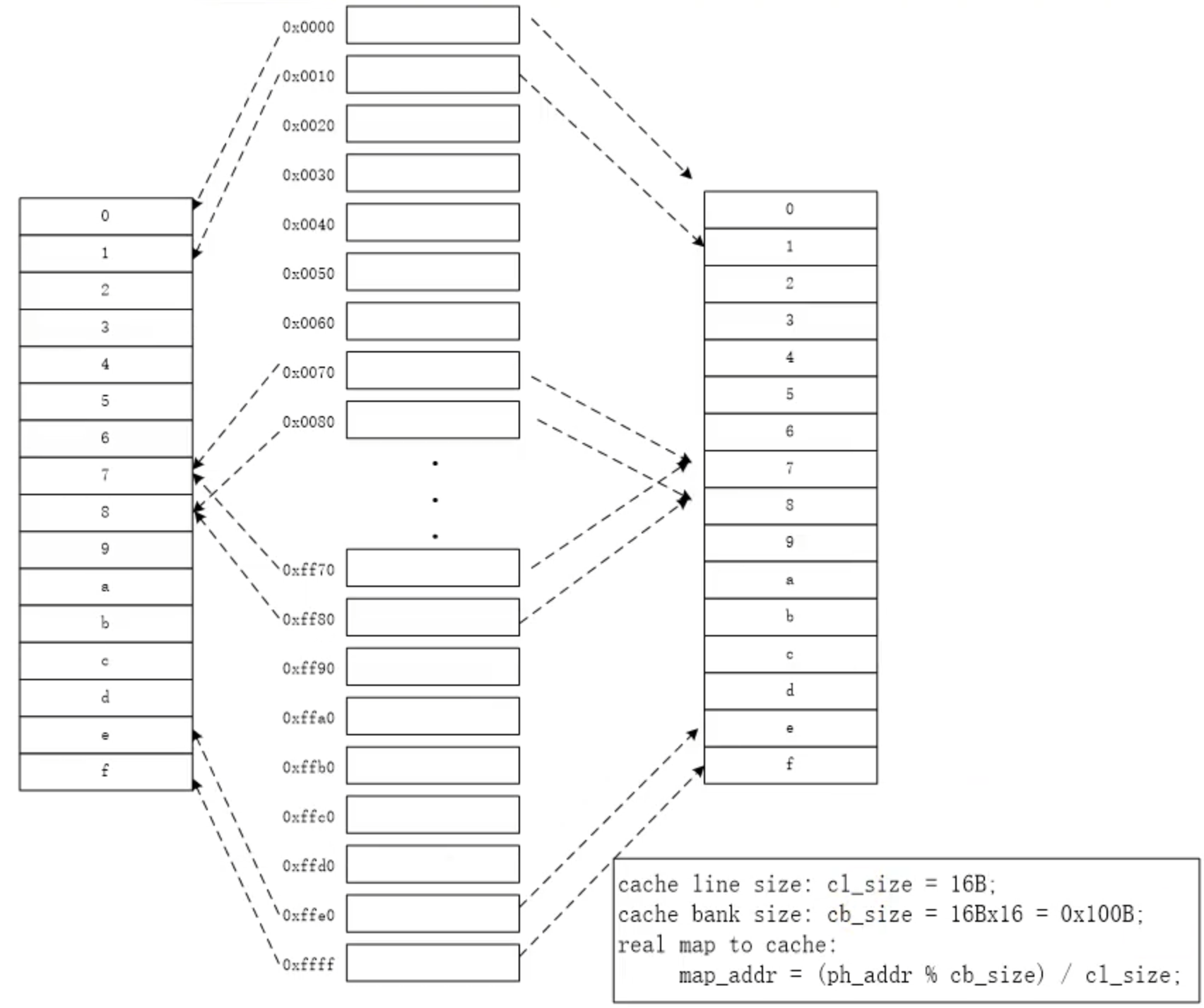
在 图 2.6 中: cache line的大小是0x10cache bank的大小是0x200
对于地址0x000的cache line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0x000 % 0x200) * 0x10
= 0
对于地址0x010的cache line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0x10 % 0x200) * 0x10
= 1
对于地址0xn0的cache_line位置是:
map_addr = (ph_addr % cb_size) * cl_size
= (0xn0 % 0x200) * 0x10
= n
第3章 缓存的一致性问题
缓存中的数据就是主存块的副本。当对缓存中的数据进行更新时,就存在缓存和主存如何保持一致性的问题。
3.1 缓存读写
对于读事务,根据目标地址的数据是否在缓存中有副本,分为hit和miss两种:
- hit:CPU想要读取的数据在cache中,可以直接从cache中读取。
- miss:CPU想要读取的数据不在cache中,需要从主存中读取,读取之后的行为有两种:
- Read Through:从主存中读取的数据,不缓存到cache。
- Read allocate:从主存中读取的数据,同时缓存到cache。
对于写事务,根据目标地址的数据是否在缓存中有副本,分为hit和miss两种:
- hit:
- Write Through:将数据同时写到主存和cache中。
- Write back: 只将数据写到cache中,只有当缓存行被失效或重新分配时,此类数据才回写到主存中。
- miss:
- Write allocate:先将数据写到主存,然后为其分配一个缓存行。
- No write allocate:直接将数据写到主存。
不推荐write back搭配 write no allocate。 前者只将数据写到缓存,后者只将数据写到主存,后续该地址的每一次访问都会是miss。
一般write back搭配 write allocate使用。 前者先将数据写到缓存,后者将数据写到主存又写到缓存,因此在第二次访问时一定会hit。
write through可以搭配 write allocate或write no allocate。
@startuml
group 读
group hit
CPU <- Cache:Read
end
group miss
group Read Allocate
Cache <- mem: Read
CPU <- mem: Read
end
group Read Through
CPU <- mem: Read
end
end
end
group 写
group hit
group Write through
CPU -> Cache:Write
CPU -> mem:Write
note over Cache #aqua
Write Through or
Write Back
end note
end
group Write back
CPU -> Cache :Write
note over Cache #aqua
Write Allocate
end note
end
end
group miss
group Write Allocate
CPU -> mem: Write
CPU -> Cache : Write
end
group Write no Allocate
CPU -> mem: Write
end
end
end
@enduml
3.2 缓存的一致性操作
cache数据一致性操作:
- clean:
- 操作:检查
dirtyflag,如果是dirty,则把cache line 的数据写到主存中,并清除 dirty, cache line仍然是valid状态。 - 应用场景:cache数据被cpu更新;某个模块需要读取这条数据,需要先clean,与其他数据保持一致。再让需求模块读取。
- 操作:检查
- invalid:
- 操作:清除
validflag,cache line中的数据直接丢掉,不写入mem。 - 应用场景:某个模块修改了终端的地址,cpu需要invalid缓存中该地址的数据,强制下次读取从主存获取数据。
- 操作:清除
- flush:
- 操作:对cache line先clean,再invalid。
- 应用场景: 应用数据的大幅度切换。