uvm实战读书笔记
uvm实战读书笔记
第1章 与uvm的第一次接触
- 验证主要保证:
- dut的行为是否与设计规格中一致。
- dut是否实现了设计规格的所有功能。
- dut对异常情况的反应是否满足如设计规格中所述。
- dut是否能够从宜昌状态恢复到正常的工作模式。
第2章 一个简单的uvm验证平台
2.1 driver
driver承担着事务驱动dut的角色。
根据类名创建一个类的实例, 这是uvm_component_utils宏所带来的效果, 同时也是factory机制给读者的最初印象。 只有在类 定义时声明了这个宏, 才能使用这个功能。
run_phase中所有耗时的语句都要加入objection raise和drop语句才能执行,否则跳过。
Note:raise_objection语句必须在main_phase中第一个消耗仿真时间的语句之前。
set和get的设置见 3.5.2 set和get的参数 。
uvm_config_db#(int)::set(null, "uvm_test_top", "var", 100);
uvm_config_db#(int)::get(this, "", "var",VAR);
Note: 使用双冒号的原因是,set和get函数是静态函数。
2.2 transaction
transaction承担着事务建模的角色。
所有的transaction都必须派生自uvm_sequence_item。这样才可以使用sequence的一些机制。
2.3 env
- env是test_top下的第一个容器类,实例化了
- driver(一个完整的环境,这个组件会实例化在agent中)
- monitor(一个完整的环境,这个组件会实例化在agent中)
- reference module
- scoreboard
build phase的建立是自上而下,也就是从test_top根,一直到各个组件的末端。
2.4 monitor
monitor承担着监控dut行为的任务。
由于monitor一直处于收集数据的状态,所以使用while(1)或forever来实现。
2.5 agent
agent承担着直接面对dut的角色。
driver和monitor的行为斗鱼dut端口信号有直接关系,在同一种协议下处理不同的事情。通常将二者封装为agent。
这里存在着一个active、passive的枚举变量,来决定是否只实例化monitor。
typedef enum bit { UVM_PASSIVE=0, UVM_ACTIVE=1 } uvm_active_passive_enum;
2.6 reference model
reference model用于完成了dut相同的功能。
reference model的关键是事务的传递,可以使用:
在monitor中例化uvm_analysis_port,要传输的事务作为参数,调用write函数。
在env中例化一个uvm_tlm_analysis_fifo,要传输的事务作为参数。
在reference model中例化analysis_port,要传输的事务作为参数。
在env的connect中
- monitor的port和env.fifo中analysis_export连接。
- reference model的port和env.fifo中analysis_get_port连接。
scoreboardscoreboard的任务是负责将参考模型的结果和dut的结果做对比。
2.7 scoreboard
scoreboard的数据来源于两个地方
- 一个是monitor
- 一个是reference model
- 同样使用uvm_tlm_analysis_fifo的方式连接。
- monitor到scoreboard
- 在monitor中例化uvm_analysis_port,要传输的事务作为参数,调用write函数。
- 在env中例化一个uvm_tlm_analysis_fifo,要传输的事务作为参数。
- 在scoreboard中例化analysis_port,要传输的事务作为参数。
- 在env的connect中
- monitor的port和env.fifo中analysis_export连接。
- scoreboard的port和env.fifo中analysis_get_port连接。
- reference model到scoreboard
- 在reference model中例化uvm_analysis_port,要传输的事务作为参数,调用write函数。
- 在env中例化一个uvm_tlm_analysis_fifo,要传输的事务作为参数。
- 在scoreboard中例化analysis_port,要传输的事务作为参数。
- 在env的connect中
- reference model的port和env.fifo中analysis_export连接。
- scoreboard的port和env.fifo中analysis_get_port连接。
- monitor到scoreboard
2.8 field_automation
将变量注册到field中,可以使用uvm的一些通用方法。
2.9 sequence和sequencer
这两者将激励产生和激励驱动分割开来。
在agent中将driver的seq_item_port连接到sequencer的seq_item_export。
sequence的body中使用宏uvm_do产生事务,包含的行为有事务例化,事务随机,事务。
一个sequence在向sequencer发送transaction前,要先向sequencer发送一个请求,sequencer把这个请求放在一个仲裁队列中。作 为sequencer,它需做两件事情:
- 第一, 检测仲裁队列里是否有某个sequence发送transaction的请求。
- 第二, 检测driver是否申请transaction。
如何在sequencer上启动sequence,有两种方法:
- 配置sequence为sequencer main_phase中的default_sequence。
- 使用sequence的start方法,sequencer作为参数。
driver使用seq_item_port的get_next_item函数获取事务。
Note:不建议使用default的方式进行设置,uvm1.2之后虽然保留了相关函数,但是sequence的starting_phase却是null,需要主动赋值。
starting_phase=get_starting_phase();
Note:get_next_item是阻塞方法,try_next_item是飞则色方法,获取不到事务则返回null。
2.10 testcase
test_casetest作为验证环境的顶层。
将env例化到test中,在test中启动sequence。
通过+UVM_TEST_NAME仿真参数指定case名字。
第3章 uvm基础
3.1 component和object
uvm_component派生自uvm_object,uvm_object是UVM中最基本的类之一。
uvm_component存在两大特性是uvm_object没有的:
- 使用parent参数构建组件结构。
- 存在phase的自动执行特点。
3.1.1 派生自uvm_object的类
uvm_sequence_item:所有的transaction要从uvm_sequence_item派生。transaction就是封装了一定信息的一个类, 本书中的my_transaction就是将一个mac帧中的各个字段封装在了一起, 包括目的地址、 源地址、 帧类型、 帧的数据、 FCS校验和等。 driver从sequencer中得到transaction,并且把其转换成端口上的信号。 虽然UVM中有一个uvm_transaction类, 但是在UVM中,不能从uvm_transaction派生一个transaction, 而要从uvm_sequence_item派生。 事实上, uvm_sequence_item是从uvm_transaction派生而来的。 因此,uvm_sequence_item相比uvm_transaction添加了很多实用的成员变量和函数或任务, 从uvm_sequence_item直接派生, 就可以使用这些新增加的成员变量和函数/任务。
uvm_sequence:所有的sequence要从uvm_sequence派生一个。sequence就是sequence_item的组合。 sequence直接与sequencer打交道,当driver向sequencer索要数据时, sequencer会检查是否有sequence要发送数据。 当发现有sequence_item待发送时, 会把此sequence_item交给driver。
config: 所有的config一般直接从uvm_object派生。config的主要功能就是规范验证平台的行为方式。 如规定driver在读取总线时地址信号要持续几个时钟,片选信号从什么时候开始有效等。 这里要注意config与config_db的区别。 在上一章中已经见识了使用config_db进行参数配置, 这里的config其实指的是把所有的参数放在一个object中,然后通过config_db的方式设置给所有需要这些参数的component。
uvm_reg_item: 它派生自uvm_sequence_item, 用于register model中。
uvm_reg_map、 uvm_mem、 uvm_reg_field、 uvm_reg、 uvm_reg_file、 uvm_reg_block 等与寄存器相关的众多的类都是派生自uvm_object, 它们都是用于register model。
uvm_phase: 它派生自uvm_object,其主要作用为控制uvm_component的行为方式, 使得uvm_component平滑地在各个不同的 phase之间依次运转。
3.1.2 派生自uvm_component的类
uvm_driver: 所有的driver都要派生自uvm_driver。 driver的功能主要就是向sequencer索要sequence_item( transaction) , 并且将sequence_item里的信息驱动到DUT的端口上, 这相当于完成了从transaction级别到DUT能够接受的端口级别信息的转换。 与uvm_component相比, uvm_driver多了如下几个成员变量:
- uvm_seq_item_pull_port #(REQ, RSP) seq_item_port;
- uvm_seq_item_pull_port #(REQ, RSP) seq_item_prod_if; // alias
- uvm_analysis_port #(RSP) rsp_port;
- REQ req;
- RSP rsp;
uvm_monitor: 所有的monitor都要派生自uvm_monitor。 monitor做的事情与driver相反, driver向DUT的pin上发送数据, 而monitor则是从DUT的pin上接收数据, 并且把接收到的数据转换成transaction级别的sequence_item, 再把转换后的数据发送给scoreboard, 供其比较。 与uvm_component相比, uvm_monitor几乎没有做任何扩充。 因此,直接从uvm_component直接派生也没关系。
uvm_sequencer: 所有的sequencer都要派生自uvm_sequencer。 sequencer的功能就是组织管理sequence, 当driver要求数据时,它就把sequence生成的sequence_item转发给driver。 与uvm_component相比, uvm_sequencer做了相当多的扩展。
uvm_scoreboard: 一般的scoreboard都要派生自uvm_scoreboard。 scoreboard的功能就是比较reference model和monitor分别发送来的数据, 根据比较结果判断DUT是否正确工作。 与uvm_monitor类似, uvm_scoreboard也几乎没有在uvm_component的基础上做扩展:
reference model: UVM中并没有针对reference model定义一个类。 所以通常来说, reference model都是直接派生自uvm_component。 reference model的作用就是模仿DUT, 完成与DUT相同的功能。 DUT是用Verilog写成的时序电路, 而reference model则可以直接使用SystemVerilog高级语言的特性, 同时还可以通过DPI等接口调用其他语言来完成与DUT相同的功能。
uvm_agent: 所有的agent要派生自uvm_agent。 与前面几个比起来, uvm_agent的作用并不是那么明显。 它只是把driver和monitor封装在一起, 根据参数值来决定是只实例化monitor还是要同时实例化driver和monitor。 agent的使用主要是从可重用性的角度来考虑的。如果在做验证平台时不考虑可重用性, 那么agent其实是可有可无的。 与uvm_component相比, uvm_agent的最大改动在于引入了一个变量is_active:
uvm_env: 所有的env( environment的缩写) 要派生自uvm_env。 env将验证平台上用到的固定不变的component都封装在一起。 这样, 当要运行不同的测试用例时, 只要在测试用例中实例化此env即可。 uvm_env也并没有在uvm_component的基础上做过多扩展:
uvm_test: 所有的测试用例要派生自uvm_test或其派生类, 不同的测试用例之间差异很大。 所以从uvm_test派生出来的类各不相同。 任何一个派生出的测试用例中, 都要实例化env, 只有这样, 当测试用例在运行的时候, 才能把数据正常地发给DUT, 并正常地接收DUT的数据。 uvm_test也几乎没有做任何扩展:
3.1.3 uvm_object相关的宏
- uvm_object_utils: 它用于把一个直接或间接派生自uvm_object的类注册到factory中。
- uvm_object_param_utils: 它用于把一个直接或间接派生自uvm_object的参数化的类注册到factory中。
- uvm_object_utils_begin uvm_object_utils_end
- uvm_object_param_utils_begin uvm_object_param_utils_end
3.1.4 与uvm_component相关的宏
- uvm_component_utils: 它用于把一个直接或间接派生自uvm_component的类注册到factory中。
- uvm_component_param_utils: 它用于把一个直接或间接派生自uvm_component的参数化的类注册到factory中。
- uvm_component_utils_begin uvm_component_utils_end
- uvm_component_param_utils_begin uvm_component_param_utils_end
3.2 uvm的树形结构
3.2.1 uvm_component的parent参数
parent参数出现在new的构造函数中,并且指定的是this,说明该组件实例化的parent是实例化位置的组件。
还存在一个m_children数组,里面存放着所有例化在该组件中的子组件。
3.2.2 uvm树的根
uvm树的叶子是各个实例化的组件,而根是top。uvm_root实例化为top。
3.2.3 层次结构相关的函数
get_parent()函数, 用于得到当前实例的parent。get_child(string name)函数,需要一个string类型的参数name, 表示此child实例在实例化时指定的名字。get_children(ref uvm_component children[$])函数,获取所有child的函数。get_first_child(string name)函数,获取第一个child。get_next_child(string name)函数,获取下一个child。get_num_children()函数,获取所有child的数量。
3.3 field automation机制
相关的宏:
- 非数组
uvm_field_int(ARG,FLAG);
uvm_field_real(ARG,FLAG);
uvm_field_enum(T,ARG,FLAG);
uvm_field_object(ARG,FLAG);
uvm_field_event(ARG,FLAG);
uvm_field_string(ARG,FLAG);
- 动态数组
uvm_field_array_enum(ARG,FLAG);
uvm_field_array_int(ARG,FLAG);
uvm_field_array_object(ARG,FLAG);
uvm_field_array_string(ARG,FLAG);
- 静态数组
uvm_field_sarray_int(ARG,FLAG);
uvm_field_sarray_enum(ARG,FLAG);
uvm_field_sarray_object(ARG,FLAG);
uvm_field_sarray_string(ARG,FLAG);
- 队列
uvm_field_queue_enum(ARG,FLAG);
uvm_field_queue_int(ARG,FLAG);
uvm_field_queue_object(ARG,FLAG);
uvm_field_queue_string(ARG,FLAG);
- 联合数组(第一个类型为索引的类型,第二个参数为存储数据的类型)
uvm_field_aa_int_string(ARG, FLAG);
uvm_field_aa_string_string(ARG, FLAG);
uvm_field_aa_object_string(ARG, FLAG);
uvm_field_aa_int_int(ARG, FLAG);
uvm_field_aa_int_int_unsigned(ARG, FLAG);
uvm_field_aa_int_integer(ARG, FLAG);
uvm_field_aa_int_integer_unsigned(ARG, FLAG);
uvm_field_aa_int_byte(ARG, FLAG);
uvm_field_aa_int_byte_unsigned(ARG, FLAG);
uvm_field_aa_int_shortint(ARG, FLAG);
uvm_field_aa_int_shortint_unsigned(ARG, FLAG);
uvm_field_aa_int_longint(ARG, FLAG);
uvm_field_aa_int_longint_unsigned(ARG, FLAG);
uvm_field_aa_string_int(ARG, FLAG);
uvm_field_aa_object_int(ARG, FLAG);
3.3.2 field automation机制常用函数
extern function void copy (uvm_object rhs);b.copy(a):a复制到b,a必须先new。extern function bit compare (uvm_object rhs, uvm_comparer comparer=null);b.compare(b):比较a和b。extern function int pack_bytes (ref byte unsigned bytestream[],input uvm_packer packer=null);a.pack_bytes(b):将a实例中的所有注册变量打包为byte类型的b。extern function int unpack_bytes (ref byte unsigned bytestream[],input uvm_packer packer=null);a.unpack_bytes(b):将byte类型的b解包为a实例中注册的变量。extern function int pack (ref bit bitstream[],input uvm_packer packer=null);a.pack(b):将a实例中的所有注册变量打包为bit类型的b。extern function int unpack (ref bit bitstream[],input uvm_packer packer=null);a.unpack(b):将bit类型的b解包为a实例中注册的变量。extern function int pack_ints (ref int unsigned intstream[],input uvm_packer packer=null);a.pack_ints(b):将a实例中的所有注册变量打包为int类型的b。extern function int unpack_ints (ref int unsigned intstream[],input uvm_packer packer=null);a.unpack_ints(b):将int类型的b解包为a实例中注册的变量。
3.3.3 field automation机制中标志位的使用
//A=ABSTRACT Y=PHYSICAL
//F=REFERENCE, S=SHALLOW, D=DEEP
//K=PACK, R=RECORD, P=PRINT, M=COMPARE, C=COPY
//--------------------------- AYFSD K R P M C
parameter UVM_ALL_ON = 'b000000101010101;
parameter UVM_COPY = (1<<0);
parameter UVM_NOCOPY = (1<<1);
parameter UVM_COMPARE = (1<<2);
parameter UVM_NOCOMPARE = (1<<3);
parameter UVM_PRINT = (1<<4);
parameter UVM_NOPRINT = (1<<5);
parameter UVM_RECORD = (1<<6);
parameter UVM_NORECORD = (1<<7);
parameter UVM_PACK = (1<<8);
parameter UVM_NOPACK = (1<<9);
3.4 uvm打印信息的控制
3.4.1 设置打印信息冗余度
UVM通过冗余度级别的设置提高了仿真日志的可读性。 在打印信息之前, UVM会比较要显示信息的冗余度级别与默认的冗 余度阈值, 如果小于等于阈值, 就会显示, 否则不会显示。 默认的冗余度阈值是UVM_MEDIUM, 所有低于等于 UVM_MEDIUM( 如UVM_LOW) 的信息都会被打印出来。
- 打印信息冗余度:
typedef enum
{
UVM_NONE = 0,
UVM_LOW = 100,
UVM_MEDIUM = 200,
UVM_HIGH = 300,
UVM_FULL = 400,
UVM_DEBUG = 500
} uvm_verbosity;
set_report_verbosity_level():设置某个组件打印信息冗余度。
get_report_verbosity_level():获取某个组件打印信息冗余度。
set_report_verbosity_level_hier:递归设置打印信息冗余度。
除了使用代码的方式设置,还可以在仿真命令中设置:<sim command> +UVM_VERBOSITY=HIGH
3.4.2 重载打印信息的严重性
- UVM默认有四种信息严重性:
- UVM_INFO
- UVM_WARNING
- UVM_ERROR
- UVM_FATAL。
这四种严重性可以互相重载。 如果要把driver中所有的UVM_WARNING显示为UVM_ERROR,可以使用如下的函数:set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR)
也可以在命令行中实现:<sim command> +uvm_set_severity=<comp>,<id>,<current severity>,<new severity>
3.4.3 uvm_error达到一定数量结束仿真
设置:set_report_max_quit_count
查询:get_report_max_quit_count函数
命令行设置:<sim command> +UVM_MAX_QUIT_COUNT=6,NO,no表示不可以被重载,yes表示可以。
3.4.4 设置计数的目标
将UVM_WARNING加入到计数目标中的组件设置:set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_COUNT)
将UVM_WARNING加入到计数目标中的递归设置:set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY|UVM_COUNT)
将"my_drv"加入到计数目标中的组件设置:set_report_id_action("my_drv", UVM_DISPLAY|UVM_COUNT)
将"my_drv"加入到计数目标中的递归设置:set_report_id_action_hier("my_drv"", UVM_DISPLAY|UVM_COUNT)
将"my_drv"和UVM_WARNING加入到计数目标中的组件设置:set_report_severity_id_action(UVM_WARNING, "my_drv", UVM_DISPLAY|UVM_COUNT)
将"my_drv"和UVM_WARNING加入到计数目标中的递归设置:set_report_severity_id_action_hier(UVM_WARNING, "my_drv", UVM_DISPLAY|UVM_COUNT)
命令行设置:<sim command> +uvm_set_action=<comp>,<id>,<severity>,<action>
3.4.5 uvm的断点功能
将 3.4.4 设置计数的目标 中的函数UVM_COUNT替换为UVM_STOP即可。
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY| UVM_STOP);
env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_STOP);
env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_STOP);
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_STOP);
env.i_agt.drv.set_report_severity_id_action(UVM_WARNING, "my_driver", UVM_DISPLAY| UVM_STOP);
env.i_agt.set_report_severity_id_action_hier(UVM_WARNING, "my_driver", UVM_DISPLAY| UVM_STOP);
命令行也是适用的。
3.4.6 将输出信息导入到文件中
定义文件
UVM_FILE info_log;
UVM_FILE warning_log;
UVM_FILE error_log;
UVM_FILE fatal_log;
写模式打开文件
info_log = $fopen("info.log", "w");
warning_log = $fopen("warning.log", "w");
error_log = $fopen("error.log", "w");
fatal_log = $fopen("fatal.log", "w");
设置文件,可通过严重性也可通过id或者两者的组合。
//非递归
env.i_agt.drv.set_report_severity_file(UVM_INFO, info_log);
env.i_agt.drv.set_report_severity_file(UVM_WARNING, warning_log);
env.i_agt.drv.set_report_severity_file(UVM_ERROR, error_log);
env.i_agt.drv.set_report_severity_file(UVM_FATAL, fatal_log);
//递归
env.i_agt.set_report_severity_file_hier(UVM_INFO, info_log);
env.i_agt.set_report_severity_file_hier(UVM_WARNING, warning_log);
env.i_agt.set_report_severity_file_hier(UVM_ERROR, error_log);
env.i_agt.set_report_severity_file_hier(UVM_FATAL, fatal_log);
输出到log文件中,可通过严重性也可通过id或者两者的组合。
//非递归
env.i_agt.drv.set_report_severity_action(UVM_INFO, UVM_DISPLAY| UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_ERROR, UVM_DISPLAY| UVM_COUNT | UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_FATAL, UVM_DISPLAY|UVM_EXIT | UVM_LOG);
//递归
env.i_agt.set_report_severity_action_hier(UVM_INFO, UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_ERROR, UVM_DISPLAY| UVM_COUNT |UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_FATAL, UVM_DISPLAY| UVM_EXIT | UVM_LOG);
3.4.7 控制打印信息的行为
行为定义:
typedef enum
{
UVM_NO_ACTION = 'b000000,
UVM_DISPLAY = 'b000001,
UVM_LOG = 'b000010,
UVM_COUNT = 'b000100,
UVM_EXIT = 'b001000,
UVM_CALL_HOOK = 'b010000,
UVM_STOP = 'b100000
} uvm_action_type;
3.5 config_db机制
3.5.1 uvm中的路径
可以使用get_full_name()方法获取路径。
为了方便,例化名和create以及new创建时指定的名字应该一致。
3.5.2 set与get函数的参数
- config_db的set和get函数都有四个参数
- 第一个参数必须是一个uvm_component实例的指针。
- 第二个参数是相对此实例的路径。
- 第三个参数表示一个记号, 用以说明这个值是传给目标中的哪个成员的。
- 第四个参数是要设置的值。
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100);
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
3.5.3 省略get语句
set与get函数一般都是成对出现, 但是在某些情况下, 是可以只有set而没有get语句, 即省略get语句。
相关的变量注册在field中,可以省略get语句。 这样使用有些前提:
- 第一, 目标组件必须使用uvm_component_utils宏注册。
- 第二, 变量必须使用相同类型的宏注册。
- 第三, 在调用set函数的时候, set函数的第三个参数必须与要get函数中变量的名字相一致。
3.5.4 跨层次的多重设置
uvm遵循:
- 近根层次优先。
3.5.5 同层次的多重设置
uvm遵循:
- 后设置优先。
3.5.6 非直线的设置和获取
获取set到或get其他组件的值,应该避免。
6.2.7 config_db对通配符的支持
路径可以使用通配符*指定,但应该避免使用,或者尽量不要太过省略。
6.2.8 check_config_usage
check_config_usage()显示出截止到此函数调用时有哪些参数是被设置过但是却没有被获取过。
6.5.9 set_config和get_config
Note:uvm1.2不支持这种操作。
set_config_int与uvm_config_db#(int)::set是完全等价的。
get_config_int与uvm_config_db#(int)::get是完全等价的。
set_config_string与uvm_config_db#(string)::set是完全等价的。
get_config_string与uvm_config_db#(string)::get是完全等价的。
set_config_object与uvm_config_db#(object)::set是完全等价的。
get_config_object与uvm_config_db#(object)::get是完全等价的。
3.5.10 config_db的调试
print_config()参数为1,表示递归查询,
参数为0,只查询当前组件爱你的config情况。
递归查询打印信息比较冗余,会遍历所有组件。
第4章 uvm中的tlm1.0通信
4.1 tlm1.0
4.1.1 验证平台内部的通信
两个组件如何通信:
- 全局变量。
- config机制去传递变量的值。
- 信箱
- 旗语
- tlm
4.1.2 tlm的定义
TLM是Transaction Level Modeling( 事务级建模) 的缩写, 它起源于SystemC的一种通信标准。
常见的术语:
- put操作:A的port将事务put到B的export。
- get操作:A的port从B的export get一个事务。
- transport操作:事务在A的port和B的export之间传递,相当于一次get和put操作。
4.1.3 uvm中的port和export
由{blocking, nonblocking, },{put, get, peek, get_peek,transport}组合,可能存在的port:
uvm_blocking_put_port#(T);
uvm_nonblocking_put_port#(T);
uvm_put_port#(T);
uvm_blocking_get_port#(T);
uvm_nonblocking_get_port#(T);
uvm_get_port#(T);
uvm_blocking_peek_port#(T);
uvm_nonblocking_peek_port#(T);
uvm_peek_port#(T);
uvm_blocking_get_peek_port#(T);
uvm_nonblocking_get_peek_port#(T);
uvm_get_peek_port#(T);
uvm_blocking_transport_port#(REQ, RSP);
uvm_nonblocking_transport_port#(REQ, RSP);
uvm_transport_port#(REQ, RSP);
get对应blocking,nonblocking,无。 put对应blocking,nonblocking,无。 get_peek对应blocking,nonblocking,无。 transport对应blocking,nonblocking,无。
15个port和15个export对应。
4.2 uvm各端口的互联
4.2.1 blocking_put系列的port和export的连接
只有发起者才能调用connect与另一个端口连接,而承担着作为connect函数的参数。
在组件中例化,在new构造函数中使用new构造。
new构造函数中包含最大和最小连接数,默认都为1:
function new(string name, uvm_component parent, int min_size = 1;int max_size = 1);
4.2.2 uvm中的imp
除了TLM中定义的PORT与EXPORT外, UVM中加入了第三种端口: IMP。 IMP才是UVM中的精髓, 承担了UVM中TLM的绝 大部分实现代码。 UVM中的IMP如下所示:
uvm_blocking_put_imp#(T, IMP);
uvm_nonblocking_put_imp#(T, IMP);
uvm_put_imp#(T, IMP);
uvm_blocking_get_imp#(T, IMP);
uvm_nonblocking_get_imp#(T, IMP);
uvm_get_imp#(T, IMP);
uvm_blocking_peek_imp#(T, IMP);
uvm_nonblocking_peek_imp#(T, IMP);
uvm_peek_imp#(T, IMP);
uvm_blocking_get_peek_imp#(T, IMP);
uvm_nonblocking_get_peek_imp#(T, IMP);
uvm_get_peek_imp#(T, IMP);
uvm_blocking_transport_imp#(REQ, RSP, IMP);
uvm_nonblocking_transport_imp#(REQ, RSP, IMP);
uvm_transport_imp#(REQ, RSP, IMP);
这15种imp和port和export是一一对应的。
前6个imp定义中
- 第一个参数T代表传输的数据类型。
- 第二个参数IMP实现此接口的组件。
Note:在UVM中, 只有IMP才能作为连接关系的终点。 如果是PORT或者EXPORT作为终点, 则会报错。
4.2.3 port和imp的连接
当类型是:
| 类型 | 需要定义的函数 |
|---|---|
| blocking_put | put() |
| nonblocking_put | try_put() can_put |
| put | put() try_put() can_put() |
| blocking_get | get() |
| nonblocking_get | try_get() can_get |
| get | get() try_get() can_get() |
| blocking_peek | peek() |
| nonblocking_peek | try_peek() can_peek |
| peek | peek() try_peek() can_peek() |
| blocking_get_peek | get_peek() |
| nonblocking_get_peek | try_get_peek() can_get_peek |
| get_peek | get_peek() try_get_peek() can_get_peek() |
| blocking_transport | transport |
| nonblocking_transport | try_transport() can_transport |
| transport | transport() try_transport() can_transport() |
nonblocking_put,需要在imp中定义函数try_put()和can_putput
A_inst.A_port.connect(B_inst.B_imp)
connect函数一定要在connect_phase中调用。
4.2.4 export和imp的连接
与 4.2.3 port和imp的连接 类似。
A_inst.A_export.connect(B_inst.B_imp);
4.2.5 port和port的连接
与 4.2.3 port和imp的连接 类似。
C_inst.C_port.connect(this.A_port);
4.2.6 export的export的连接
与 4.2.3 port和imp的连接 类似。
C_inst.C_export.connect(this.A_export);
4.2.7 blocking_get端口的使用
函数在动作发起者实现,哟普动作接受者调用。
Note: 在这些连接关系中, 需要谨记的是连接的终点必须是一个IMP。
4.2.8 blocking_transport的使用
在imp端实现一个transport的函数:transport(my_transaction req, output my_transaction rsp);
4.2.9 nonblocking端口的使用
nonblocking端口的所有操作都是非阻塞的, 换言之, 必须用函数实现, 而不能用任务实现。 有两个函数:
- try
- can
4.3 uvm中的通信方式
4.3.1 uvm中的analysis端口
UVM中还有两种特殊的端口: analysis_port和analysis_export。 相比于put、get、peek系列的端口:
- 默认情况下,一个analysis_port可以连接多个analysis_imp,属于一对多的通信。
- 属于广播端口,因此没有阻塞和非阻塞的概念。
- 只有一种操作write,在imp定义。
4.3.2 一个component中有多个imp
使用uvm_analysis_imp_decl生成多个imp,以应对多个port或者export对多个imp的连接。
相应的,write函数也需要实现多个。
4.3.3 使用fifo通信
fifo的本质是一块缓存加两个imp。
FIFO中有两个IMP, 但是在实际的连接关系中, FIFO中却是EXPORT,这是因为
- FIFO中的export虽然名字中有关键字export, 但是其类型却是IMP。
- UVM为了掩饰IMP的存在, 在它们的命名中加入了export关键字。
使用fifo的好处是不必在scoreboard中再写一个名字为write的函数,fifo中自己实现了事务传递的函数。
4.3.4 fifo上的端口及调试
fifo有两种:
- uvm_tlm_analysis_fifo
- uvm_tlm_fifo(无analysis_export端口和write函数)
uvm_tlm_analysis_fifo上存在着众多的端口 图 4.1 。
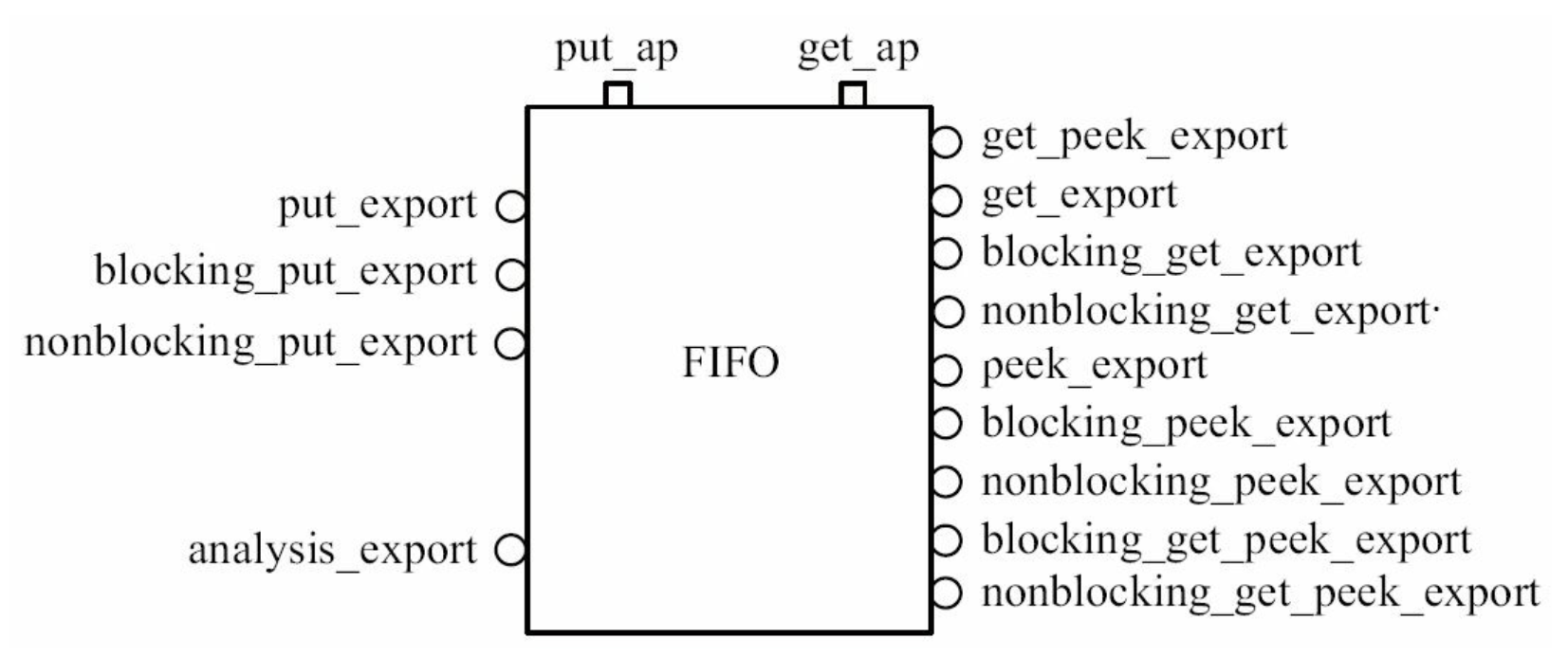
在图 图 4.1 中:
- export的本质都是imp。
- 包含除transport之外的12种imp和两个analysis_port{put_ap和get_ap}。
- 12种imp用于和port和export连接。
- 当analysis_port/export调用put时,把事务放在fifo的缓存中,会调用fifo中put_ap.write()函数把事务发送出去。
- 当analysis_port/export调用get时,请求把事务放在fifo的缓存中,会调用fifo中get_ap.write()函数把事务发送出去。
- get的每次调用都会使fifo的事务少一份,peek则不会。
uvm提供了几个用于fifo调试的函数:
- used:缓存中有多少事务。
- is_empty:缓存是否为空。
- is_full:缓存是否为满。
- flush:清空fifo缓存中的事务。
默认情况fifo缓存大小为1,可在new函数中指定。
4.3.5 用fifo还是imp
在用FIFO通信的方法中,完全隐藏了IMP这个UVM中特有、 而TLM中根本就没有的东西。 但却增加了env中代码的复杂度。
在需要端口数组的时候,fifo比imp要好用,imp需要多次指定后缀,fifo使用数组的方法一次生成多个fifo。
第5章 uvm验证平台的使用
5.1 phase机制
5.1.1 task phase和function phase
function phase:不消耗时间。
- build
- connect
- end_of_elaboration
- start_of_simulation
- extract_phase
- check_phase
- report_phase
- final_phase
task phase:消耗时间。
- run_phase
- pre_reset_phase
- reset_phase
- post_reset_phase
- pre_configure_phase
- configure_phase
- post_configure_phase
- pre_main_phase
- main_phase
- post_main_phase
- pre_shutdown_phase
- shutdown_phase
- post_shutdown_phase
run_phase和对应的12个task phase是并行的,这12个task phase是串行的。
5.1.2 run phase
- reset_phase对DUT进行复位、 初始化等操作。
- configure_phase则进行DUT的配置。
- DUT的运行主要在main_phase完成。
- shutdown_phase则是做一些与DUT断电相关的操作。
5.1.3 phase的执行顺序
不同组件的phase是按照自下而上,也就是叶到根的方式执行。 同层次的phase是严格按照字典序,也就是new时指定的名字执行的。
- 多个层次的task phase,他们是同时开始的,先执行完的phase需要等待后执行完的phase才能进入下一个phase。
5.1.4 uvm树的遍历
可能存在两种执行方式:
- 广度优先:先执行同层次的所有组件的phase,再执行子组件的phase
- 深度优先:按照深度执行组件的以及子组件的phase,再执行同层次的phase。
uvm使用的是深度优先方式,也就是先执行agent以及driver、monitor等的phase再执行scb的phase。
Note:agent和scb的先后是按照字典序的先后执行的。
5.1.5 super.phase的内容
除了build之外,其他phase几乎没做任何相关的事情。
build_phase使用apply_config_settings方法完成了 3.5.3 省略get语句 的自动get。
在uvm_factory创建组建时,检查uvm_resources中是否存有与该组件相关的配置信息,
如果有的话,那么该组件中的相关变量的默认值会被覆盖为高层的配置值。
5.1.6 build阶段出现uvm_error停止仿真
build阶段中出现uvm_error也会停止仿真,只是在log中以uvm_fatal的形式出现,这是uvm内部定义的。
build阶段的这种error变fatal的机制,对于大型仿真非常有用。 毕竟build关系整个平台的运行,可以在运行之前就发现问题。
5.1.7 phase的跳转
可以使用下面的方式执行当前phase到reset_phase的跳转:phase.jump(uvm_reset_phase::get());
Note:只有具有先后关系的phase才可以跳转,例如main_phase和run_phase就不可以跳转。
5.1.8 phase机制的必要性
phase的机制:
- 避开了部分代码的书写顺序要求,强制将不同块的代码按顺序组织起来。
- 主动承担起了组件之间顺序自动执行的角色,减少了验证平台开发者的工作量。
5.1.9 phase的调试
可以使用命令行的方式打开phase的调试<sim command> +UVM_PHASE_TRACE。
5.1.10 超时退出
可以使用top的超时设置函数进行设置21 uvm_top.set_timeout(500ns, 0);。
- 第一个参数是设置的时间。
- 第二个参数表示是否可以被其后的set_timeout覆盖。
- 默认是9200s
也可以通过命令行设置:
<sim command> +UVM_TIMEOUT=<timeout>,<overridable>
5.2 objection机制
5.2.1 objection与task phase
objection字面的意思就是反对、 异议。
为了良好的沟通, 在drop_objection之前, 一定要先raise_objection。
objection是针对phase的一种机制,同一phase的组件可以都raise、drop,也可以只有一个组件raise、drop。
5.2.2 参数phase的重要性
在UVM中所有phase的函数/任务参数中, 都有一个phase参数。
这个参数的主要目的是raise_objection。 为了确保所有组件的phase同步,必须通过phase.raise_objection来完成。
5.2.3 控制objection的最佳选择
driver、 monitor、reference_model、scoreboard一般都是无限循环while(1)实现的。
推荐在sequence中raise、drop,这也符合uvm对sequence控制激励生成的要求。
5.2.4 set_drain_time的使用
在sequence中,发送完激励立刻停止是不推荐的。 一般情况下,dut处理激励需要时间,因此在发送完激励之后,需要延迟一段时间,确保数据都处理完毕。
phase.phase_done.set_drain_time(this,100);可以确保drop之后经历100个时间单位之后结束phase。
5.2.5 objection的调试
与phase的调试一样, UVM同样提供了命令行参数来进行objection的调试:
<sim command> +UVM_OBJECTION_TRACE
5.3 domain的使用
5.3.1 多domain的简介
domain是UVM中一个用于组织不同组件的概念。
在默认情况下, 验证平台中所有component都位于一个名字为common_domain的domain中。 若要体现出独立性, 那么两个部分 的reset_phase、 configure_phase、 main_phase等就不应该同步。 此时就应该让其中的一部分从common_domain中独立出来, 使其位于不同的domain中。
domain把两块时钟域隔开, 之后两个时钟域内的各个动态运行( run_time) 的phase就可以不必同步。 注意, 这里domain只能 隔离run-time的phase, 对于其他phase, 其实还是同步的, 即两个domain的run_phase依然是同步的, 其他的function phase也是同步 的。
5.3.2 多domain的例子
新建一个domain, 并将其实例化。 在connect_phase中通过set_domain将B加入到此domain中。
class B extends uvm_component;
uvm_domain new_domain;
`uvm_component_utils(B)
function new(string name, uvm_component parent);
super.new(name, parent);
new_domain = new("new_domain");
endfunction
virtual function void connect_phase(uvm_phase phase);
set_domain(new_domain);
endfunction
…
endclass
set_domain的第二个参数表示是否递归。
5.3.3 多domain的phase跳转
phase跳转只能在自己的domain中。
第6章 uvm中的sequence
6.1 sequence基础
6.1.1 从driver中剥离激励产生功能
单独使用sequence对DUT施加不同的激励。
6.1.2 sequence的启动和执行
启动:
- start任务
my_sequence my_seq;
my_seq = my_sequence::type_id::create("my_seq");
my_seq.start(sequencer);
- default_sequence
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
case0_sequence::type_id::get());
- 实例化,再设置default_sequence
case0_sequence caseq;
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
caseq);
启动: 设置好了之后,会自动调用pre_body、body、post_body
6.2 sequence的仲裁机制
6.2.1 在同一个sequence上启动多个sequence
在my_sequencer上同时启动了两个sequence: sequence1和sequence2:
fork
seq0.start(env.i_agt.sqr);
seq1.start(env.i_agt.sqr);
join
sequencer根据什么选择使用哪个sequence的transaction呢? 这是UVM的sequence机制中的仲裁问题。 可以通过uvm_do_pri及uvm_do_pri_with改变所产生的transaction的优先级。
为sequencer设置仲裁算法:env.i_agt.sqr.set_arbitration(UVM_SEQ_ARB_STRICT_FIFO);,
sequencer的仲裁算法:
UVM_SEQ_ARB_FIFO:默认,遵循先入先出的顺序, 而不会考虑优先级。UVM_SEQ_ARB_WEIGHTED:加权的仲裁。UVM_SEQ_ARB_RANDOM:完全随机。UVM_SEQ_ARB_STRICT_FIFO:严格按照优先级,存在同一优先级,按照fifo先进先出。UVM_SEQ_ARB_STRICT_RANDOM:严格按照优先级,存在同一优先级,随机。UVM_SEQ_ARB_USER:用户自定义算法,需要重载user_priority_arbitration()
3.2.2 sequence的lock操作
当多个sequence在一个sequencer上同时启动时, 每个sequence产生出的transaction都需要参与sequencer的仲裁。 那么考虑这样一种情况, 某个sequence比较奇特, 一旦它要执行, 那么它所有的transaction必须连续地交给driver, 如果中间夹杂着其他sequence的transaction, 就会发生错误。 可以使用lock操作锁定sequence。
直接在sequence的body中使用lock()锁定当前sequencer,直到unlock()。
6.2.3 sequencer的grab操作
grab操作和lock类似,也是仲裁的独占。
- lock操作是先仲裁,再锁定。
- grab操作是先锁定。
6.2.4 sequence的有效性
通过lock任务和grab任务, sequence可以独占sequencer, 强行使sequencer发送自己产生的transaction。 同样的, UVM也提供措 施使sequence可以在一定时间内不参与仲裁, 即令此sequence失效。
每次仲裁之前,都会查看被仲裁sequence的is_relevant()是否有效。
如果有效,则参与仲裁;如果无效,则放弃仲裁,并且调用wait_for_relevant()等待有效。
需要重载的函数:
- 重载
is_relevant()。 - 重载
wait_for_relevant(),否则会报错。
6.3 sequence相关宏及其实现
6.3.1 uvm_do系列宏
uvm_do(SEQ_OR_ITEM)
uvm_do_pri(SEQ_OR_ITEM, PRIORITY)
uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)
uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
uvm_do_on(SEQ_OR_ITEM, SEQR)
uvm_do_on_pri(SEQ_OR_ITEM, SEQR, PRIORITY)
uvm_do_on_with(SEQ_OR_ITEM, SEQR, CONSTRAINTS)
uvm_do_on_pri_with(SEQ_OR_ITEM, SEQR, PRIORITY, CONSTRAINTS)
6.3.2 uvm_create与uvm_send
uvm_create宏的作用是实例化事务。
事务处理完成之后,
uvm_send宏发送事务,也可以用uvm_send_pri宏发送事务同时设定优先级。
6.3.3 uvm_rand_send系列宏
uvm_rand_send宏与uvm_send宏类似, 唯一的区别是它会对transaction进行随机化。
系列宏:
uvm_rand_send(SEQ_OR_ITEM)
uvm_rand_send_pri(SEQ_OR_ITEM, PRIORITY)
uvm_rand_send_with(SEQ_OR_ITEM, CONSTRAINTS)
uvm_rand_send_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
如果一个transaction占用的内存比较大, 那么很可能希望前后两次发送的transaction都使用同一块内存, 只是其中的内容可以不同, 这样比较节省内存
6.3.4 start_item和finish_item
不使用宏产生transaction的方式要依赖于两个任务: start_item和finish_item。
对事物的处理应当在事务例化之后,finish_item之前。start_item之前之后都可以。
在这里也可以使用第二个参数指定优先级,两个函数都要指定。
6.3.5 pre_do、mid_do和post_do
- pre_do是一个任务, 是start_item返回前执行的最后一行代码, 在它执行完毕后才对transaction进行随 机化。
- mid_do是一个函数, 位于finish_item的最开始。 在执行完此函数后, finish_item才进行其他操作。
- post_do也是一个函数, 是finish_item返回前执行的最后一行代码。 它们的执行顺序大致为:
sequencer.wait_for_grant(prior) (task) \
start_item \
parent_seq.pre_do(1) (task) / \
`uvm_do* macros
parent_seq.mid_do(item) (func) \ /
sequencer.send_request(item) (func) \ /
finish_item /
sequencer.wait_for_item_done() (task) /
parent_seq.post_do(item) (func) /
使用时,需要重载这三个函数。
6.4 sequence的进阶应用
6.4.1 嵌套的sequence
一个sequence内启动另外一个sequence, 这就是嵌套的sequence。
crc_seq cseq;
long_seq lseq;
repeat (10) begin
`uvm_do(cseq)
`uvm_do(lseq)
6.4.2 在sequence中使用rand类型
在sequence中也可以使用rand修饰符。
Note:变量名一定要和事务中的变量名有所区别。
6.5.3 transaction类型的匹配
一个sequencer只能产生一种类型的transaction。 一个sequence如果要想在此sequencer上启动, 那么其所产生的transaction的类型必须是这种transaction或者派生自这种transaction。
如果想将两个截然不同的transaction交给同一个sequencer产生,
只需要将sequencer和driver能够接受的数据类型设置为uvm_sequence_item,并且driver中手动执行cast转换$cast(my_tr, req)。
6.4.4 p_sequencer的使用
m_sequencer是case0_sequence在启动后所使用的sequencer的指针,属于uvm_sequencer_base基类。
可以使用cast将其转换为当前sequencer,$cast(x_sequencer, m_sequencer)。
在实际的验证平台中,更推荐使用宏uvm_declare_p_sequencer(SEQUENCER)
声明一个指向当前sequence的p_sequencer,宏内部也做了类型转换。
6.4.5 sequence的派生和集成
由于在同一个项目中各sequence都是类似的, 所以可以将很多公用的函数或者任务写在base sequence中, 其他sequence都从此sequence派生。
6.5 virtual sequence的使用
6.5.1 带双路输入输出端口的dut
dut存在两组端口,需要使用两个interface以及构建两个env。
6.5.2 sequence之间的简单同步
两个env之间的driver是等价的,处于某种原因需要再第一个env发送某个包,才能发送第二个env的事务。 可以使用全局事件来同步。
6.5.3 sequence之间的复杂同步
实现sequence之间同步的最好的方式就是使用virtual sequence。 从字面上理解, 即虚拟的sequence。 虚拟的意思就是它根本就不发送transaction, 它只是控制其他的sequence, 起统一调度的作用。一般需要一个virtual sequencer。
virtual sequencer和virtual sequence里面包含了sequencer和sequence的指针。
virtual sequencer例化在test层,且在connect_phase中和对应env下的sequencer进行连接。
6.5.4 仅在virtual sequence中控制objection
建议在最顶层的virtual sequence进行raise和drop操作。
6.5.5 在sequence中慎用fork join_none
当使用for加fork join_none启动多个sequence时,应使用wait fork去等待所有的sequence执行完毕再进行后续的操作。
6.6 在sequence中使用config_db
6.6.1 在sequence中获取参数
一般config_db set的对象都是component,针对sequence也提供了支持。
- set:路径使用通配符,
uvm_config_db#(int)::set(this, "env.i_agt.sqr.*", "count", 9) - get:使用
get_full_name()获取路径,uvm_config_db#(int)::get(null, get_full_name(), "count", count)
Note:在get函数原型中, 第一个参数必须是一个component, 而sequence不是一个component, 所以这里不能使用this指针, 只能使用null或者uvm_root: : get( ) 。 前文已经提过, 当使用null时, UVM会自动将其替换为 uvm_root: : get( ) , 再加上第二个参数get_full_name( ) , 就可以完整地得到此sequence的路径, 从而得到参数。
6.6.2 在sequence中设置参数
在sequence中为scb设置参数:
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.env0.scb","cmp_en", 0);
6.6.3 wait_modified的使用
如果不做任何处理的话, 6.6.2 在sequence中设置参数 章节设置的参数在scb是get不到的,这是因为get一般在build中调用。
针对这种不固定的设置参数的方式, UVM中提供了wait_modified任务, 它的参数有三个, 与config_db: : get的前三个参数完 全一样。 当它检测到第三个参数的值被更新过后, 它就返回, 否则一直等待在那里。
task my_scoreboard::main_phase(uvm_phase phase);
fork
while(1) begin
uvm_config_db#(bit)::wait_modified(this, "", "cmp_en");
void'(uvm_config_db#(bit)::get(this, "", "cmp_en", cmp_en));
`uvm_info("my_scoreboard", $sformatf("cmp_en value modified, the new value is %0d", cmp_en),
end
join
endtask
6.7 response的使用
6.7.1 put_response和get_response
sequence机制提供对driver给sequence反馈的支持, 它允许driver将一个response返回给sequence。
在driver的item_done之前put_response(rsp)。
在sequence的body中get_response(rsp)。
如果存在多个sequence,则需要对rsp事务进行set_id_info(req)。
6.7.2 response的数量问题
通常来说, 一个transaction对应一个response, 但是事实上, UVM也支持一个transaction对应多个response的情况, 在这种情况 下, 在sequence中需要多次调用get_response, 而在driver中, 需要多次调用put_response。
然而sequencer可接受的response队列的最大数量默认是8个,多于8个就会报错。
get_response(rsp)是阻塞的。
6.7.3 response handle与另类的response
sequence中发送transaction与get_response是在同一个进程中执行的,。 假如将二者分离开来, 在不同的进程中运行将会得到不同的结果。 在这种情况下需要使用response_handler。
- 在sequence中打开response_handle的功能:
use_response_handler(1) - 在sequence中重载函数response_handler,在其中实现对rsp的操作。
virtual function void response_handler(uvm_sequence_item response)
if(!$cast(rsp, response))
`uvm_error("seq", "can't cast")
else begin
`uvm_info("seq", "get one response", UVM_MEDIUM)
rsp.print();
end
endfunction
6.7.4 rsp个req类型不同
在前面章节的例子中只向它们传递了一个参数, 因此response与req的类型是一样的。 如果要使用不同类型的rsp与req, 那么 driver、 sequencer与sequence在定义时都要传入两个参数。这样rsp和req的类型就可以不同。
6.8 sequence library
6.8.1 随机选择sequence
所谓sequence library, 就是一系列sequence的集合。 sequence_library本质上就是一个sequence,因此定义时也需要指定发送的事务为参数。
使用步骤:
- 从uvm_sequence_library派生。
- 初始化:
init_sequence_library - 在library中注册:
uvm_sequence_library_utils(sequence_library) - 在sequence中添加:
uvm_add_to_seq_lib(seq,sequence_library)
6.8.2 控制选择算法
sequence中的selection_mode变量决定选择什么算法。
typedef enum
{
UVM_SEQ_LIB_RAND, //完全的随机
UVM_SEQ_LIB_RANDC, //序列随机
UVM_SEQ_LIB_ITEM, //作为一个普通sequence,不执行内部的sequence
UVM_SEQ_LIB_USER //自定义算法,需重载sekect_sequence(MAX)。
} uvm_sequence_lib_mode;
6.8.3 控制执行次数
sequence library会在min_random_count和max_random_count之间随意选择一个数来作为执行次数。 这两个参数属于sequence。
6.8.4 使用sequence_library_cfg
UVM提供了一个类uvm_sequence_library_cfg来对sequence library进行配置。 它一共有三个成员变量:
- uvm_sequence_lib_mode selection_mode;
- int unsigned min_random_count;
- int unsigned max_random_count
在new的时候,传递对应参数。然后直接将config传递给相应的sequence_library, 或者给sequence_library的变量直接赋值。
第7章 uvm中的寄存器模型
7.1 寄存器模型介绍
7.1.1 带寄存器配置总线的dut
存在这样一个dut,
- 只有一个1bit的寄存器invert, 为其分配地址16’h9。
- 如果它的值为1, 那么DUT在输出时会将输入的数据取反;
- 如果为0, 则将输入数据直接发送出去。
- bus_op为1时表示写操作, 为0表示读操作。
- bus_addr表示地址,
- bus_rd_data表示读取的数据。
- bus_wr_data表示要写入的数据。
- bus_cmd_valid为1时表示总线数据有效, 只持续一个时钟, DUT应该在其为1期间采样总线数据;
- 如果是读操作, 应该在下一个时钟给出读数据。
- 如果是写操作, 应该在下一个时钟把数据写入。
7.1.2 需要寄存器模型才能做的事情
有了寄存器模型后, 可以在任何耗费时间的phase中使用寄存器模型以前门访问或后门( BACKDOOR) 访问的方式来读取寄存器的值, 同时还能在某些不耗费时间的phase( 如check_phase) 中使用后门访问的方式来读取寄存器的值。
前门访问与后门访问是两种寄存器的访问方式。
- 所谓前门访问, 指的是通过模拟cpu在总线上发出读指令, 进行读写操作。 在这个过程中, 仿真时间( $time函数得到的时间) 是一直往前走的。
- 而后门访问是与前门访问相对的概念。 它并不通过总线进行读写操作, 而是直接通过层次化的引用来改变寄存器的值。
7.1.3 寄存器模型的基本概念
寄存器模型的组成单位:
- uvm_reg:一个寄存器,存在至少一个uvm_reg_field。
- uvm_reg_field:寄存器模型的最小单位。
- uvm_reg_block:存在多个uvm_reg或者uvm_reg_block。
- uvm_reg_map:将寄存器的偏移地址映射为硬件的物理地址。每个uvm_reg_block至少存在一个uvm_reg_map。
7.2 简单的寄存器模型
7.2.1 只有一个寄存器的寄存器模型
在reg的build函数中配置reg_field的configure参数:
- parent, //一般为this,表示属于该寄存器
- size,
- lsb_pos,
- access, //访问类型,只读、只写、读写等
- volatile,
- reset value,
- has_reset,
- is_rand,
- individually_accessible,是否可单独存取。
在reg_block的build函数中实例化创建寄存器,配置寄存器的configure:
- 此寄存器所在uvm_reg_block的指针, 这里填写this
- 第二个参数是reg_file的指针,这里暂时填写null。
- 第三个参数是此寄存器的后门访问路径,这里暂且为空。
并调用寄存器的build函数。创建default_map并添加寄存器。
7.2.2 将寄存器模型集成到验证平台中
派生adapter
寄存器模型的前门访问操作可以分成读和写两种。 无论是读或写, 寄存器模型都会通过sequence产生一个uvm_reg_bus_op的变量。
uvm_reg_bus_op通过adapter转换为bus的事务后,交给sequencer,通过driver驱动给dut。 需要实现两个函数:
- reg2bus,寄存器事务转换为总线事务。
- bus2reg,总线事务转换为寄存器事务。
集成到test中
在test中:
- 实例化寄存器模型:
- 调用configure函数。
- 调用build函数。
- 调用lock_model函数。
- 调用reset函数复位所有寄存器。
- 实例化转换器。
在sequencer也实例化寄存器模型,并且在test的connect_phase中与创建的寄存器模型进行连接。
还要为寄存器模型的map设置sequencer和转换器,设置自动预测。
rm.default_map.set_sequencer(env.bus_agt.sqr, reg_sqr_adapter);
7.2.3 在验证平台中使用寄存器模型
有两个基本的函数,read()和write()。常用前三个函数:
- 状态;
- 数据;
- 前门后门,默认是UVM_DEFAULT_PATH
7.3 前门访问和后门访问
7.3.1 uvm中前门访问的实现
所谓前门访问操作就是通过寄存器配置总线( 如APB协议、 OCP协议、 I2C协议等)来对DUT进行操作,只有读操作和写操作。
转换器的bus2reg和reg2bus提供了一种uvm_reg_item和总线transaction的转换,以读操作为例:
- 参考模型调用寄存器模型的读任务。
- 寄存器模型产生sequence, 并产生uvm_reg_item: rw。
- 产生driver能够接受的transaction: bus_req=adapter.reg2bus(rw) 。
- 把bus_req交给bus_sequencer。
- driver得到bus_req后驱动它, 得到读取的值, 并将读取值放入bus_req中, 调用item_done。
- 寄存器模型调用adapter.bus2reg(bus_req, rw) 将bus_req中的读取值传递给rw。
- 将rw中的读数据返回参考模型
对于 6.7 response的使用 ,转换器也提供了相应的机制。 在adapter中设置provide_responses选项。
- 参考模型调用寄存器模型的读任务。
- 寄存器模型产生sequence, 并产生uvm_reg_item: rw。
- 产生driver能够接受的transaction: bus_req=adapter.reg2bus(rw) 。
- 将bus_req交给bus_sequencer。
- driver得到bus_req, 驱动它, 得到读取的值, 并将读取值放入rsp中, 调用item_done。
- 寄存器模型调用adapter.bus2reg(rsp, rw) 将rsp中的读取值传递给rw。
- 将rw中的读数据返回参考模型。
7.3.2 uvm中后门访问的实现
在通信系统中, 有大量计数器用于统计各种包裹的数量, 如超长包、 长包、 中包、 短包、 超短包等。 这些计数器的一个共同的特点是它们是只读的, DUT的总线接口无法通过前门访问操作对其进行写操作。
从广义上来说, 所有不通过DUT的总线而对DUT内部的寄存器或者存储器进行存取的操作都是后门访问操作。
后门访问的好处:
- 后门访问操作能够更好地完成前门访问操作所做的事情,且不消耗仿真时间。
- 后门访问操作能够完成前门访问操作不能完成的事情。对只读寄存器的写。
后门访问的坏处:
- 无法在波形上看到操作哼唧,很大程度上依赖验证平台的打印信息。
7.3.3 使用interface进行后门访问
直接对接口中的端口进行访问。
7.3.4 uvm中后门访问的视线:dpi+vpi
这种方式适用于有对dut进行后门访问的需求,但是不向使用寄存器模型。
除了寄存器和接口的后门访问操作,还有使用c代码对寄存进行访问的需求。
verilog提供了两个vpi接口函数:
vpi_get_value(obj, p_value);vpi_put_value(obj, p_value, p_time, flags);
system_verilog提供了更好的dpi接口。
- 在c中定义:
int uvm_hdl_read(char *path, p_vpi_vecval value); - 在sv中import:
import "DPI-C" context function int uvm_hdl_read(string path, output uvm_hdl_d ata_t value);
7.3.5 uvm后门访问操作接口
在uvm_reg_block调用uvm_reg的configure函数时,设置好第三个路径参数。
在test集成时,设置好根路径参数。
uvm提供两类后门访问:
- UVM_BACKDOOR形式的write和read,模仿dut的行为,受寄存器读写类型的影响。
- peek和poke:纯粹的后门访问,不受dut行为的影响。 无论是peek还是poke, 其常用的参数都是前两个。 各自的第一个参数表示操作是否成功, 第二个参数表示读写的数据。
7.4 复杂的寄存器模型
7.4.1 层次化寄存器模型
在现实中通常会出现将uvm_reg_block再加入一个uvm_reg_block中的情况, 然后在base_test中实例化后者。
集成过程和reg集成在reg_block中的相似:
- 第一步是先实例化子reg_block。
- 第二步是调用子reg_block的configure函数。 如果需要使用后门访问, 则在这个函数中要说明子reg_block的路径, 这个路径不是绝对路径, 而是相对于父reg_block来说的路径( 简单起见, 上述代码中的路径参数设置为空字符串, 不能发起后门访问操作) 。
- 第三步是调用子reg_block的build函数。
- 第四步是调用子reg_block的lock_model函数。
- 第五步则是将子reg_block的default_map以子map的形式加入父reg_block的default_map中。
7.4.2 reg_file的作用
UVM的寄存器模型中还有一个称为uvm_reg_file的概念。 这个类的引入主要是用于区分不同的hdl路径。 uvm_reg_file同uvm_reg相同是一个纯虚类, 不能直接使用, 而必须使用其派生类。
class regfile extends uvm_reg_file;
function new(string name = "regfile");
super.new(name);
endfunction
`uvm_object_utils(regfile)
endclass
然后在reg_block中创建,configure:
- 第一个参数是其所在的reg_block的指针。
- 第二个参数是假设此reg_file是另外一个reg_file的父文件, 那么这里就填写其父reg_file的指针。 由于这里只有这一级reg_file, 因此填写null。
- 第三个参数则是此reg_file的hdl相对路径。
7.4.3 多个域的寄存器
前面所有例子中的寄存器都是只有一个域的, 如果一个寄存器有多个域时, 那么在建立模型时会稍有改变。
域相当于寄存器内部的字段分属于不同的路径。
设某个寄存器有三个域, 其中最低两位为filedA, 接着三位为filedB, 接着四位为filedC, 其余位未使用。
这个寄存器从逻辑上来看是一个寄存器, 但是从物理上来看, 即它的DUT实现中是三个寄存器, 因此这一个寄存器实际上对 应着三个不同的hdl路径: fieldA、 fieldB、 fieldC。
当寄存器存在多个域时,需要再寄存器build之后使用add_hdl_path_slice()进行域的分割:
- 这个函数的第一个参数是要加入的路径。
- 第二个参数则是此路径对应的域在此寄存器中的起始位数, 如fieldA是从0开始的, 而fieldB是从2开始的。
- 第三个参数则是此路径对应的域的位宽。
7.4.4 多个地址的寄存器
有些寄存器的位宽比总线的位宽要大,因此寄存器模型可能需要多个地址。
寄存器模型提供另外一种方式, 可以使一个寄存器占据多个地址:
- 将占据多个地址的寄存器单独按实际位宽进行定义。
- default_map按实际的总线定义。
- 总线读取时会从偏移地址开始读,分多次,直到寄存器的位宽全部读到。
7.4.5 加入存储器
直接派生uvm_mem,new函数比较特殊:
- 第一个是名字。
- 第二个是存储器的深度。
- 第三个是宽度。
在block中创建,configure:
- 第一个参数是所在reg_block的指针。
- 第二个参数是此块存储器的hdl路径。
最后调用default_map.add_mem函数, 将此块存储器加入default_map中。
在对mem进行write、read、peek、poke操作时,需要指定一个offset的偏移地址,指定读取位置。
假如存储器的宽度大于系统总线位宽时,总线会访问多次。
7.5 寄存器模型对dut的模拟
7.5.1 期望值和镜像值
镜像值:寄存器模型中有一个专门的变量用于最大可能地与DUT保持同步。 期望值:寄存器模型期望dut应该表现的值。
写寄存器有两种方法:
- 直接
write():期望值和镜像值都更新。 - 两步写:
- 先
set(),更新期望值。get()函数可以得到期望值。 - 再
update(),如果镜像值和期望值不一致,则更新镜像值。get_mirrored()可以得到镜像值。
- 先
对于存储器来说,不存在这两个值。
7.5.2 常用操作及其对期望值和镜像值的影响
- read&write操作:无论通过后门访问还是前门访问的方式从DUT中读取或写入寄存器的值, 在操作完成后, 寄存器模型都会根据读写的结果更新期望值和镜像值( 二者相等) 。
- peek&poke操作:在操作完成后, 寄存器模型会根据操作的结果更新期望值和镜像值( 二者相等)
- get&set操作:set操作会更新期望值, 但是镜像值不会改变。 get操作会返回寄存器模型中当前寄存器的期望值。
- update操作:这个操作会检查寄存器的期望值和镜像值是否一致, 如果不一致, 那么就会将期望值写入DUT中, 并且更新镜像值, 使其与期望值一致。 每个由uvm_reg派生来的类都会有update操作。 每个由uvm_reg_block派生来的类也有update操作, 它会递归地调用所有加入此reg_block的寄存器的update任务。
- randomize操作: 寄存器模型提供randomize接口。 randomize之后, 期望值将会变为随机出的数值, 镜像值不会改变。 这需要寄存器创建时configure支持。
7.6 寄存器模型中一些内建的sequence
start时,指定的sequencer为null。
如果不想检查某个寄存器,可以:
uvm_resource_db#(bit)::set({"REG::",rm.invert.get_full_name(),".*"},"NO_REG_TESTS", 1, this);
如果不想检查寄存器的某项检查,可以:
uvm_resource_db#(bit)::set({"REG::",rm.invert.get_full_name(),".*"},"NO_REG_HW_RESET_TEST", 1, this);
7.6.1 检查后门访问中hdl路径的sequence
uvm_reg_mem_hdl_paths_seq
7.6.2 检查默认值的sequence
uvm_reg_hw_reset_seq
7.6.3 检查读写功能的sequence
uvm_reg_access_seq和uvm_mem_access_seq
7.7 寄存器模型的高级用法
7.1 使用reg_predictor
driver返回读取值后,寄存器模型自动更新寄存器的期望值和镜像值,这个功能被称为寄存器模型的自动预测,是由下面的代码打开的rm.default_map.set_auto_predict(1)
还有一种手动的方式,monitor将总线上收集到的事务交给寄存器模型,后者主动更新期望值和镜像值。 需要实例化一个reg_predictor,并为这个预测期例化一个adapter。这个adapter和driver使用的是一个。
在connect_phase中, 需要将reg_predictor的bus_in和bus_agt的ap口连接在一起, 并设置reg_predictor的adapter和map。只有设置了map后, 才能将predictor和寄存器模型关联在一起。
reg_predictor.map = rm.default_map;
reg_predictor.adapter = mon_reg_adapter;
env.bus_agt.ap.connect(reg_predictor.bus_in);
这样就存在两条更新寄存器模型的路径:
- 一条是自动预测。
- 一条是主动预测。
7.7.2 使用uvm_predict_direct功能与mirror操作
mirror
UVM提供mirror操作, 用于读取DUT中寄存器的值并将它们更新到寄存器模型的镜像值和期望值。 第二个参数指的是如果发现DUT中寄存器的值与寄存器模型中的镜像值不一致, 那么在更新寄存器模型之前是否给出错误提示。 其可选的值为UVM_CHECK和UVM_NO_CHECK。
它有两种应用场景:
- 一是在仿真中不断地调用它, 使得到整个寄存器模型的值与DUT中寄存器的值保持一致, 此时check选项是关闭的。
- 二是在仿真即将结束时, 检查DUT中寄存器的值与寄存器模型中寄存器的镜像值是否一致, 这种情况下, check选项是打开的。
predict
使用predict()人为地更新镜像值, 但是同时又不要对DUT进行任何操作。
- 其中第一个参数表示要预测的值,
- 第二个参数是byte_en, 默认-1的意思是全部有效,
- 第三个参数是预测的类型,
UVM_PREDICT_DIRECTUVM_PREDICT_READUVM_PREDICT_WRITE
- 第四个参数是后门访问或者是前门访问。 第三个参数预测类型有如下几种可以选择:
read/peek和write/poke操作在对DUT完成读写后, 也会调用此函数, 只是它们给出的参数是UVM_PREDICT_READ和UVM_PREDICT_WRITE。 要实现在参考模型中更新寄存器模型而又不影响DUT的值, 需要使用UVM_PREDICT_DIRECT, 即默认值。
7.7.3 寄存器模型的随机化和update
随机化可以在以下三个层次调用:
- uvm_reg_field
- uvm_reg
- uvm_reg_block
随机化会更新寄存器的期望值,然后使用update更新寄存器的镜像值。
7.7.4 扩展位宽
寄存器模型的最大位宽为64,通过宏UVM_REG_DATA_WIDTH和UVM_REG_ADDR_WIDTH控制。
7.8 寄存器模型的其他常用函数
7.8.1 get_root_blocks函数
get_root_blocks(blks)函数得到验证平台上所有的根块( root block) 。 根块指最顶层的reg_block。
在使用get_root_blocks函数得到reg_block的指针后, 要使用cast将其转化为目标reg_block形式( 示例中为reg_model) 。 以后就 可以直接使用p_rm来进行寄存器操作, 而不必使用p_sequencer.p_rm。
7.8.2 get_reg_by_offset函数
使用`get_reg_by_offset()函数通过寄存器的地址得到一个uvm_reg的指针, 再调用此uvm_reg的read或者write就可以进行读写操作。
第8章 uvm中的factory机制
8.1 systemverilog对重载的支持
8.2 任务与函数的重载
面向对象语言都有一大特征: 重载。 当在父类中定义一个函数/任务时, 如果将其设置 为virtual类型, 那么就可以在子类中重载这个函数/任务。
重载的最大优势是使得一个子类的指针以父类的类型传递时, 其表现出的行为依然是子类的行为。
8.1.2 约束的重载
对约束的重载可以不要添加virtual关键字。
8.2 使用factory机制进行重载
8.2.1 factory机制的重载
实现重载的要求:
- 都要在定义时注册到factory机制中。
- 被重载的类(bird) 在实例化时, 要使用factory机制式的实例化方式。
- 重载的类必须派生自被重载的类。
- component与object之间互相不能重载.
8.2.2 重载的方式及种类
位于uvm_component中:
set_type_override_by_type、set_type_override:
- 第一个参数是被重载的类型或名字。
- 第二个参数是重载的类型或名字。
- 第三个参数是replace,表示是否可以被后面的重载覆盖。
set_inst_override_by_type、set_inst_override:
- 第一个参数是相对路径。
- 第二个参数是被重载的类型或名字。
- 第三个参数是要重载的类型或名字。
位于uvm_factory中:
set_type_override_by_type、set_type_override_by_name:- 第一个参数是被重载的类型或名字。
- 第二个参数是重载的类型或名字。
- 第三个参数是replace,表示是否可以被后面的重载覆盖。
set_inst_override_by_type、set_inst_override_by_name:- 第一个参数是被重载的类型或名字。
- 第二个参数是要重载的类型或名字。
- 第三个参数是相对路径。
也可以使用命令行的方式重载:
+uvm_set_inst_override=<req_type>,<override_type>,<full_inst_path>+uvm_set_type_override=<req_type>,<override_type>[,<replace>]
8.2.3 复杂的重载
连续重载:
set_type_override_by_type(bird::get_type(), parrot::get_type());
set_type_override_by_type(parrot::get_type(), big_parrot::get_type());
替换重载:
set_type_override_by_type(bird::get_type(), parrot::get_type());
set_type_override_by_type(bird::get_type(), sparrow::get_type());
8.2.4 factory机制的调试
component中可以打印组件的重载信息的函数:
env.o_agt.mon.print_override_info("my_monitor");
factory中可以打印组件重载信息的函数:
uvm_factory.print(<0,1,2>)
- 当为0时, 仅仅打印被重载的实例和类型。
- 当为1时, 打印参数为0时的信息, 以及所有用户创建的、 注册到factory的类的名称。
- 当为2时, 打印参数为1时的信息, 以及系统创建的、 所有注册到factory的类的名称( 如uvm_reg_item)。
top中打印拓扑结构的函数:
uvm_top.print_topology();
8.3 常用的重载
8.3.1 重载transaction
8.3.2 重载sequence
8.3.3 重载component
8.3.4 重载driver以实现所有的测试用例
8.4 factory机制的实现
8.4.1 创建一个类实例的方法
直接创建:
class A
… e
ndclass
class B;
A a;
function new();
a = new();
endfunction
endclass
参数化创建:
class parameterized_class # (type T)
T t;
function new();
t = new();
endfunction
endclass
class A;
… e
ndclass
class B;
parameterized_classs#(A) pa;
function new();
pa = new();
endfunction
endclass
8.4.2 根据字符串创建类
8.4.3 用factory机制创建实例的接口
create_object_by_name()和create_object_by_type():
- 一般只使用第一个参数
create_component_by_name()和create_component_by_type:
- 第一个参数是字符串类型的类名/类型。
- 第二个参数是父结点的全名。
- 第三个参数是为这个新的component起的名字。
- 第四个参数是父结点的指针。
8.4.4. factory机制的本质
从本质上来看, factory机制其实是对SystemVerilog中new函数的重载。 因为这个原始的new函数实在是太简单了, 功能太少了。 经过factory机制的改良之后, 进行实例化的方法多了很多。
经过factory机制的改良之后, 进行实例化的方法多了很多。 这也体现了UVM编写的一个原则, 一个好的库应该提供更多方便实用的接口, 这种接口一方面是库自己写出来并开放给用户的, 另外一方面就是改良语言原始的接口, 使得更加方便用户的使用。
第9章 uvm代码中的可重用性
9.1 callback机制
在UVM验证平台中, callback机制的最大用处就是提高验证平台的可重用性。
很多情况下, 验证人员期望在一个项目中开发的验证平台能够用于另外一个项目。 但是, 通常来说, 完全的重用是比较难实现的, 两个不同的项目之间或多或少会有一些差异。 如果把两个项目不同的地方使用callback函数来做, 而把相同的地方写成一个完整的env,
9.1.1 广义的callback函数
post_randomize函数是SystemVerilog提供的广义的callback函数。 UVM也为用户提供了广义的callback函数/任务: pre_body和post_body, 除此之外还有pre_do、 mid_do和post_do。
9.1.2 callback机制的必要性
callback机制为固定的程序提供了一些灵活的接口。
9.1.3 uvm中callback机制的原理
在使用的时候, 只要从A派生一个类并将其实例化, 然后加入到A_pool中, 那么系统运行到上面的foreach( A_pool[i]) 语句时, 将会知道加入了一个实例, 于是就会调用其pre_tran函数( 任务) 。
有了A和A_pool, 真正的callback机制就可以实现了。 UVM中的callback机制与此类似, 不过其代码实现非常复杂。
9.1.4 callback机制的使用
- 从uvm_callback派生一个类,类中实现一个相关的虚函数。
class A extends uvm_callback; virtual task pre_tran(my_driver drv, ref my_transaction tr); endtask function new(string name= "my_callback"); super.new(name); endfunction endclass - 从A派生一个类,将其中的虚函数实现。
class my_callback extends A; virtual task pre_tran(my_driver drv, ref my_transaction tr); `uvm_info("my_callback", "this is pre_tran task", UVM_MEDIUM) endtask `uvm_object_utils(my_callback) function new(string name= "my_callback"); super.new(name); endfunction endclass - 在使用位置driver中将使用callback的类和声明的callback类注册:
`uvm_register_cb(my_driver, A) - 在connect_phase中add:
uvm_callbacks#(my_driver, A)::add(env.i_agt.drv, my_cb); - 调用callback函数:
`uvm_do_callbacks(my_driver, A, pre_tran(this, req))- uvm_do_callbacks宏的第一个参数是调用pre_tran的类的名字, 这里自然是my_driver,
- 第二个参数是哪个类具有pre_tran, 这里是A,
- 第三个参数是调用的是函数/任务, 这里是pre_tran, 在指明是pre_tran时, 要顺便给出pre_tran的参数
9.1.5 子类继承父类的callback机制
使用了uvm_set_super_type宏, 它把子类和父类关联在一起。
- 第一个参数是子类,
- 第二个参数是父类。
在子类调用使,与父类相同,在main_phase中调用uvm_do_callbacks宏时,
- 第一个参数是my_driver, 而不是new_driver。
9.1.6 使用callback函数来实现所有的测试用例
将激励产生以一个callback的形式实现,就可以完全代替sequence。
9.1.7 callback机制、sequence机制和factory机制
callback机制、 sequence机制和factory机制在某种程度上来说很像: 它们都能实现搭建测试用例的目的。
9.2 功能的模块化,小而美
9.2.1 linux的设计哲学,小而美
小而美的本质是功能模块化、 标准化,
小而美的前提是功能模块划分要合理, 一个不合理的划分是谈不上美的
9.2.2 小而美与factory机制的重载
factory机制重要的一点是提供重载功能。 一般来说, 如果要用B类重载A类, 那么B类是要派生自A类的。 在派生时, 要保留A类的大部分代码, 只改变其中一小部分。
9.2.3 放弃建造强大sequence的想法
强烈建议不要使用强大的sequence。 可以将一个强大的sequence拆分成小的sequence。
9.3 参数化的类
代码的重用分为很多层次。 凡是在某个项目中开发的代码用于其他项目, 都可以称为重用, 如:
- A用户在项目P中的代码被A用户自己用于项目P。
- A用户在项目P中的代码被A用户自己用于项目Q。
- A用户在项目P中的代码被B用户用于项目Q。
- A用户在项目P中开发的代码被B用户或者更多的用户用于项目P或项目Q。
为了增加代码的可重用性, 参数化的类是一个很好的选择。
9.3.2 uvm对参数化类的支持
UVM对参数化类的支持首先体现在factory机制注册上。 例如uvm_object_param_utils和uvm_component_param_utils这两个用于参数化的object和参数化的component注册的宏。
UVM的config_db机制可以用于传递virtual interface。 SystemVerilog支持参数化的interface:
interface bus_if#(int ADDR_WIDTH=16, int DATA_WIDTH=16)(input clk, input rst_n)
...
uvm_config_db#(virtual bus_if#(16, 16))::set(null, "uvm_test_top.env.bus_agt.mon", "vif" bif);
...
uvm_config_db#(virtual bus_if#(ADDR_WIDTH, DATA_WIDTH))::get(this, "", "vif", vif)
uvm同样支持参数化的object或者component:
class bus_sequencer#(int ADDR_WIDTH=16, int DATA_WIDTH=16) extends uvm_sequen cer #(bus_transaction#(AD
class bus_agent#(int ADDR_WIDTH=16, int DATA_WIDTH=16) extends uvm_agent ;
...
bus_agent bus_agt;
...
bus_agt = bus_agent#(16, 16)::type_id::create("bus_agt", this);
9.4 模块级到芯片级的代码重用
9.4.1 基于env的重用
当在芯片级别验证时, 如果采用env级别的重用, 那么B和C中的driver分别取消, 这可以通过设置各自i_agt的is_active来控制。
在验证平台中, 每个模块验证环境需要在其env中添加一个analysis_port用于数据输出; 添加一个analysis_export用于数据输 入; 在env中设置in_chip用于辨别不同的数据来源:
- 如果该env是输入env,则将来自外部用于数据输入的analysis_export连接agt_mdl_fifo的export。
- 如果该env是输出env,则将来自内部用于数据输入的i_agt.ap连接到agt_mdl_fifo的export。
9.4.2 寄存器模型的重用
为了在芯片级别使用寄存器模型, 需要建立一个新的寄存器模型。 这个新的寄存器模型中只需要加入各个不同模块的寄存器模型并设置偏移地址和后门访问路径:
class chip_reg_model extends uvm_reg_block;
rand reg_model A_rm;
rand reg_model B_rm;
rand reg_model C_rm;
virtual function void build();
default_map = create_map("default_map", 0, 2, UVM_BIG_ENDIAN, 0);
default_map.add_submap(A_rm.default_map, 16'h0);
...
default_map.add_submap(B_rm.default_map, 16'h4000);
...
default_map.add_submap(C_rm.default_map, 16'h8000);
...
endfunction
endclass
在env层例化寄存器模型并且将各个模块的指针赋值给env的寄存器模型。
9.4.3 virtual sequence和virtual sequencer
无论是内部模块还是边界模块, 统一推荐其virtual sequencer在base_test中实例化。 在芯片级别建立自己的virtual sequencer。
有两种模块级别的sequence可以直接用于芯片级别的验证。
- 一种如A、 D和F这样的边界输入端的普通的sequence( 不是virtual sequence)。
- 另外一种是寄存器配置的sequence。
第10章 uvm高级应用
10.1 interface
10.1.1 interface实现driver的部分功能
在interface中可以定义任务与函数。 除此之外, 还可以在interface中使用always语句和initial语句。
使用interface代替driver的第一个好处是可以让driver从底层繁杂的数据处理中解脱出来, 更加专注于处理高层数据。 第二个好处是有更多的数据出现在interface中, 这会对调试起到很大的帮助。
10.1.1 可变时钟
可变时钟有三种:
- 第一种是在不同测试用例之间时钟频率不同, 但是在同一测试用例中保持不变。
在一些应用中, 如HDMI协议中, 其图像的时钟信号就根据发送( 接收) 图像的分辨率的变化而变化。 当不同的测试用例测试不同分辨率的图像时, 就需要在不同测试用例中设置不同的时钟频率。 - 第二种是在同一个测试用例中存在时钟频率变换的情况。 芯片上的时钟是由PLL产生的。 但是PLL并不是一开始就会产生稳定的时钟, 而是会有一段过渡期, 在这段过渡期内, 其时钟频率是一直变化的。 有时候不关心这段过渡期时, 而只关心过渡期前和过渡期后的时钟频率。
- 第三种可变时钟和第二种很像, 但是它既关心过渡期前后的时钟, 也关心PLL在过渡期的行为。
对于第一种可变时钟,有两种方式可以实现可变时钟:
- 将时钟生成单独作为一个模块。
module top_tb(); … `include "test_clk.sv" … endmodule - 在test层set,在top层get,参数化生成可变时钟。
class test1 extends uvm_test; function void my_case0::build_phase(uvm_phase phase); … uvm_config_db#(real)::set(this, "", "clk_half_period", 200.0); endfunction endclass module top; ... #1;//set,get都是在0时刻开始的。 if(uvm_config_db#(real)::get(uvm_root::get(), "uvm_test_top", "clk_half_period", clk_half_period) `uvm_info("top_tb", $sformatf("clk_half_period is %0f", clk_half_per iod), UVM_MEDIUM) ... endmodule
对于第二种可变时钟可以使用下面的方法:
- 在top层:
module top;
...
initial begin
static real clk_half_period = 100.0;
clk = 0;
fork
forever begin
uvm_config_db#(real)::wait_modified(uvm_root::get(), "uvm_test_to p", "clk_half_period");
void'(uvm_config_db#(real)::get(uvm_root::get(), "uvm_test_top", " clk_half_period", clk_h
`uvm_info("top_tb", $sformatf("clk_half_period is %0f", clk_half_p eriod), UVM_MEDIUM)
end
forever begin
#(clk_half_period*1.0ns) clk = ~clk;
end
join
end
- 在testcase层:
task my_case0::main_phase(uvm_phase phase);
#100000;
uvm_config_db#(real)::set(this, "", "clk_half_period", 200.0);
#100000;
uvm_config_db#(real)::set(this, "", "clk_half_period", 150.0);
endtask
对于第三种时钟生成方式:
- 可以根据组件的并行运行特性,专门创建一个时钟接口和时钟组件,并在env例化,独自运行。
class clk_model extends uvm_component;
`uvm_component_utils(clk_model)
virtual clk_if vif;
real half_period = 100.0;
…
function void build_phase(uvm_phase phase);
super.build_phase(phase);
if(!uvm_config_db#(virtual clk_if)::get(this, "", "vif", vif))
`uvm_fatal("clk_model", "must set interface for vif")
void'(uvm_config_db#(real)::get(this, "", "half_period", half_perio d));
`uvm_info("clk_model", $sformatf("clk_half_period is %0f", half_peri od), UVM_MEDIUM)
endfunction
virtual task run_phase(uvm_phase phase);
vif.clk = 0;
forever begin
#(half_period*1.0ns) vif.clk = ~vif.clk;
end
endtask
endclass
class my_env extends uvm_env;
…
clk_model clk_sys;
…
virtual function void build_phase(uvm_phase phase);
…
clk_sys = clk_model::type_id::create("clk_sys", this);
…
endfunction
…
endclass
在需要新的时钟模型时, 只需要从clk_model派生一个新的类,然后在新的类中实现时钟模型。 使用factory机制的重载功能将clk_model用新的类重载掉。 通过这种方式, 可以将时钟设置为任意想要的行为。
10.2 layer sequence
10.2.1 复杂sequence的简单化
多个sequence负责一个包的部分。
10.2.2 layer sequence的实例
在seqr2中使用uvm_seq_item_pull_port获取其他seqr1产生的seq1:
- 在sequencer中创建port,参数是目标事务:
uvm_seq_item_pull_port #(ip_transaction) ip_tr_port; - 在agent中将两个sequencer进行连接:
sqr.ip_tr_port.connect(ip_sqr.seq_item_export)
第二个seq2使用while循环不断地通过seqr2的pull_port获取seqr1产生的seq1进行加工, 加工之后交给driver进行驱动。
10.2.3 layer sequence和try_next_item
try_next_item使用于下面情况:
- 在正式传送之前,需要发送一些空闲数据。
- 在正式传送完成item_done的drain_time,也需要发送一些空闲数据。
需要调用uvm_wait_for_nba_region()来避免driver的try_next_item调用过早,第1层的seq1还没准备好driver就try_next_item()。
10.2.4 错峰技术的使用
假如上述layer sequence又多了一层, 达到3层,只增加一个uvm_wait_for_nba_region()是没有用处的。
多次调用也不太合理。
归根结底,问题的关键在于item_done和try_next_item是在同一时刻被调用, 这导致了时间槽的竞争, 可以在item_done被调用后, 并不是立即调用try_next_item, 而是等待下一个时钟的上升沿到来后再调用。
10.3 sequence的其他问题
10.3.1 心跳功能的实现
在某些协议中, 需要driver每隔一段时间向DUT发送一些类似心跳的信号。 这些心跳信号的包与其他的普通的包并没有本质上的区别, 其使用的transaction也都是普通的transaction。
有两种方法:
- 在driver中与get_item的进程并行另开一个进行去发送心跳包。
- 使用sequence的方式:
- 单独为心跳包创建一个sequence,其中使用while(1)加grab-ungrab的方式独占sequencer,这里也要raise和drop。
- test中将心跳sequence与正常sequence同时启动。
10.3.2 只将virtual sequence设置为default sequence
如果只将virtual sequence设置为default_sequence, 那么所有其他的sequence都在其中启动。 其中带来的一个好处是向sequence传递参数更加方便。
10.3.3 disable fork对原子操作的影响
UVM寄存器模型的write操作是原子操作,不允许中途中断。 因此不应该在寄存器操作未完成时disable 带有寄存器读写操作的fork。
可以使用旗语的get、put和try_get语句。
- 先new一个旗语
- 使用fork json同时开两个并行线程。
- 在寄存器操作之前
try_get(1),第一次一定返回1,执行下面的寄存器操作,完成之后put(1)。 - 在正常的sequence中阻塞
get(1)。 - 当
get(1)返回时,寄存器进程try_get(1)返回0,由else分支去break。
10.4 dut参数的随机化
10.4.1 使用寄存器模型随机化参数
可以使用寄存器模型的随机化及update来为DUT选择一组随机化的参数。
assert(p_rm.randomize());
p_rm.updata(status, UVM_FRONTDOOR);
缩小随机化的范围:
- 只将需要随机化的寄存器调用randomize函数。
assert(p_rm.reg1.randomize() with { reg_data.value == 5'h3;}); assert(p_rm.reg2.randomize() with { reg_data.value >= 7'h9;}); - 调用整体的randomize函数时, 为需要指定参数的寄存器指定约束:
assert(p_rm.randomize() with {reg1.reg_data.value == 5'h3; reg2.reg_data.value >= 7'h9}); - 借助于factory机制的重载功能, 从需要随机的寄存器中派生一个新的类。
class dreg1 extends my_reg1; constraint{ reg_data.value == 5'h3; } endclass class dreg2 extends my_reg2; constraint{ reg_data.value >= 7'h9; } endclass
10.4.2 使用单独的参数类
在一个验证平台中, 需要用到寄存器的地方有如下三个:
- 一是RTL代码中。
- 二是SystemVerilog中。
- 三是C语言中。
必须时刻保持这三处的寄存器完全一致。 当一处有更新时, 其他两处必须相应更新。 寄存器成百上千个, 如果全部手工来做这些事情, 将会非常耗费时间和精力。 因此一般的IC公司会将寄存器的描述放在一个源文件中, 如word文档、 excel文件、 xml文档中, 然后使用脚本从中提取寄存器信息, 并分别生成相应的RTL代码、 UVM中的寄存器模型及C语言中的寄存器模型。 当寄存器更新时, 只更新源文件即可, 其他的可以自动更新。 这种方式省时省力, 是主流的方式。
为了解决这个问题, 可以针对DUT中需要随机化的参数建立一个dut_parm类, 并在其中指定默认约束:
class dut_parm extends uvm_object;
reg_model p_rm;
…
rand bit[15:0] a_field0;
rand bit[15:0] b_field0;
constraint ab_field_cons{
a_field0 + b_field0 >= 100;
}
task update_reg();
p_rm.rega.write(status, a_field0, UVM_FROTDOOR);
p_rm.regb.write(status, b_field0, UVM_FROTDOOR);
endtask
endclass
这段代码中指定了一个update_reg任务, 它用于当参数随机化完成后, 把相关的参数更新到DUT中。 在virtual sequence中, 可以实例化这个新的类, 随机化并调用update_reg任务。
10.5 聚合参数
10.5.1 聚合参数的定义
在验证平台中用到的参数有两大类:
- 一类是验证环境与DUT中都要用到的参数, 这些参数通常都对应DUT中的寄存器,可以将这些参数组织成了一个参数类。
- 另外一类是验证环境中独有的, 比如driver中要发送的preamble数量的上限和下限。 本节讲述如何组织这类参数。
一种比较好的方法就是将这1000个变量放在一个专门的类里面来实现,使用约束去规定参数。配置时只传递配置类。
10.5.2 聚合参数的优势和问题
使用聚合参数后, 可以将此参数类的指针放在virtual sequencer中。 sequence可以动态地改变某个验证平台中的变量值。 某些情况下, 甚至可以将interface也放入此聚合参数类。
这种将所有参数聚合起来的做法可以大大方便验证平台的搭建。 将这个聚合类的指针赋值给任意component, 这样这些 component再也不需要使用config_db: : get函数来获取参数了。 当验证平台的某个组件( 如driver) 要增加一个参数时, 只需要在 这个聚合类中加入此参数, 在测试用例中直接为其赋值, 然后在验证平台( 如driver) 中就可以直接使用。
10.6 config_db
10.6.1 换一个phase使用config_db
在前面的介绍中, 使用config_db几乎都是在build_phase中。
一个component的路径可以通过get_full_name()来获得。
但是在build_phase时, 整棵UVM树还没有形成, 使用env.i_agt.drv的形式进行引用会引起空指针的错误。 所以, 要想这么使 778用, 有两种方法:
- 一种是所有的实例化工作都在各自的new函数中完成。
- 第二种方式是将
uvm_config_db::set()移到connect_phase中去。 由于connect_phase是由下向上执行的,test的connect_phase几乎是最后执行的, 因此应该在end_of_elaboration_phase或者start_of_simulation_phase调用uvm_config_db::get()。
10.6.2 config_db的替代者
config_db设置的参数有两种,
- 一种是结构性的参数, 如控制driver是否实例化的参数is_active。
- 另一种是非结构性的参数, 如向某个driver中传递某个参数。 可以完全在build_phase之后的任意phase中使用绝对路径引用进行设置。
10.6.3 set函数的第二个参数检查
config_db机制的 最大问题在于不对set函数的第二个参数进行检查。 本节介绍一个函数, 可以在一定程度上( 并不能检查所有! ) 实现对第二个参 数有效性的检查。 读者可以将这个函数加入到自己的验证平台中。
Note: 需要说明的是, 这个函数有一些局限, 其中之一就是不支持
config_db::set()向object传递的参数。